Rocksdb简介
起源
RocksDB项目是起源于Facebook,是一款作为各种存储介质上的服务器工作负载的存储引擎,最初专注于快速存储(尤其是闪存存储)。它是一个 C++ 库,用于存储任意大小的字节流的键和值。它支持点查找和范围扫描,并提供不同类型的 ACID 保证。 在可定制性和自适应性之间取得平衡。RocksDB 具有高度灵活的配置设置,可以调整为在各种生产环境中运行,包括 SSD、硬盘、ramfs 或远程存储。它支持各种压缩算法和良好的生产支持和调试工具。另一方面,还努力限制旋钮的数量,提供足够好的开箱即用性能,并在适用的地方使用一些自适应算法。
RocksDB 借鉴了开源leveldb项目的重要代码以及Apache HBase的想法。最初的代码是从开源 leveldb 1.5 fork出来的。
很多项目都接纳了RocksDB作为其后端存储的一种解决方案,如Mysql, Ceph, Flink, MongoDB, TiDB等。
项目链接:
leveldb: https://github.com/google/leveldb
rocksdb: https://github.com/facebook/rocksdb
关于LSM树
LSM树,即日志结构合并树(Log-Structured Merge-Tree)。其实它并不属于一个具体的数据结构,它更多是一种数据结构的设计思想。大多NoSQL数据库核心思想都是基于LSM来做的,只是具体的实现不同。
传统关系型数据库使用btree或一些变体作为存储结构,能高效进行查找。但保存在磁盘中时它也有一个明显的缺陷,那就是逻辑上相离很近但物理却可能相隔很远,这就可能造成大量的磁盘随机读写。随机读写比顺序读写慢很多,为了提升IO性能,我们需要一种能将随机操作变为顺序操作的机制,于是便有了LSM树。
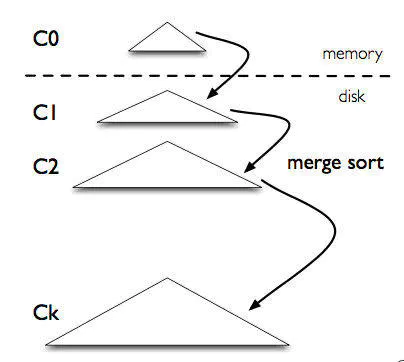
从概念上说,最基本的LSM是很简单的 。将之前使用一个大的查找结构(造成随机读写,影响写性能),变换为将写操作顺序的保存到一些相似的有序文件(也就是sstable)中。所以每个文件包 含短时间内的一些改动。因为文件是有序的,所以之后查找也会很快。文件是不可修改的,他们永远不会被更新,新的更新操作只会写到新的文件中。读操作检查很 有的文件。通过周期性的合并这些文件来减少文件个数。
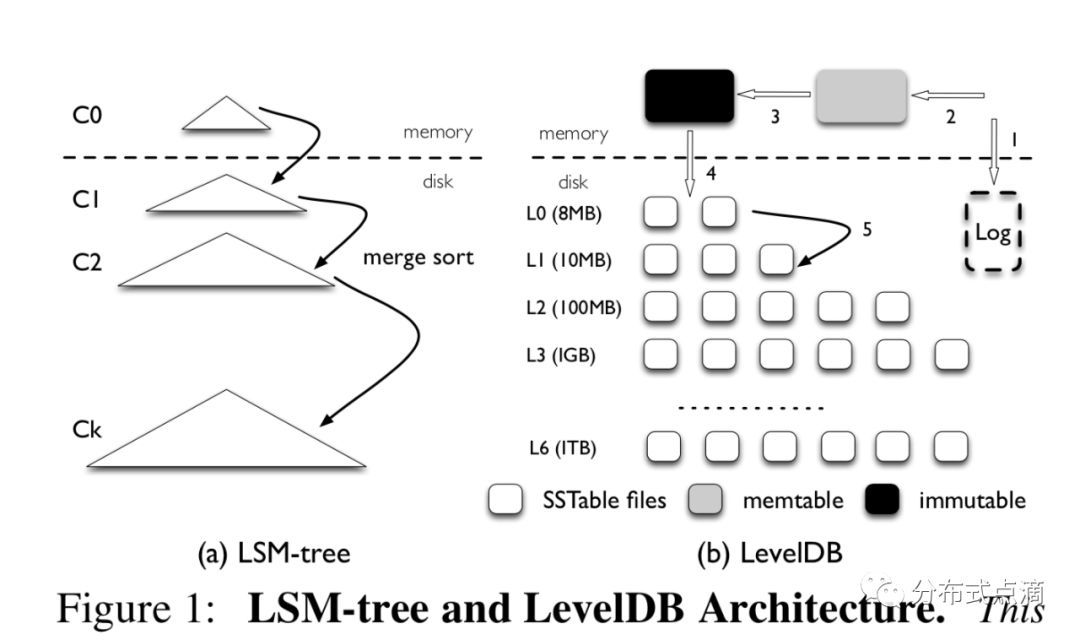
架构
RocksDB 是一个基于键值对存储接口的存储引擎库,其中键和值是任意字节流。RocksDB 将所有数据按排序顺序组织起来,常用的操作有Get(key), NewIterator(), Put(key, val), Delete(key), 和SingleDelete(key)。
RocksDB 的三个基本结构是memtable、sstfile和logfile。memtable是一种内存数据结构 - 新的写入被插入到memtable中,并且可以选择写入日志文件(又名。Write Ahead Log(WAL))。日志文件是存储上按顺序写入的文件。当 memtable 填满时,它会被刷新到存储上的sstfile,并且可以安全地删除相应的日志文件。对 sstfile 中的数据进行排序以方便查找键。
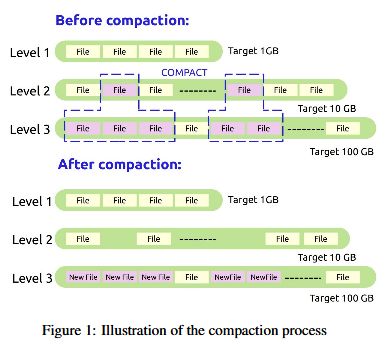
RocksDB使用布隆过滤器来判定键在哪个sst文件中。为了避免随机写,它将数据积累到内存中的memtable中,然后一次性刷写到硬盘中。RocksDB的文件是不可变的,一旦生成就不会继续写该文件。记录不会被更新或者删除,会生成一个新文件。这会在硬盘生成一些多余的数据,会需要数据库Compaction(压缩),Compaction文件会移除冗余的键值对并腾出空间,如图所示
RocksDB用不同的排列组织数据,也就是层level,每层都有个目标大小,每层的目标大小增长倍数是相同的,默认是10倍,因此,如果第一层目标大小1g,那么2,3,4层大小就是10g,100g,1000g,一个键可能出现在不同的层,随着compaction,但是越新的值层越高,越旧的值层越低。
RocskDB和LevelDB的区别
结构和levelDB大同小异,只是多了一些改进
- 增加了column family,有了列簇的概念,可把一些相关的key存储在一起
- 内存中有多个immute memtalbe,可防止Leveldb中的 write stall(写停顿)
- 可支持多线程同时compaction,理论上多线程同时compction会比一个线程compaction要快
- 支持TTL过期淘汰机制
- flush与compation分开不同的线程池来调度,并具有不同的优先级,flush要优于compation,这样可以加快flush,防止stall
- 对SSD存储做了优化,可以以in-memory方式运行
- 增加了对 write ahead log(WAL)的管理机制,更方便管理WAL,WAL是binlog文件
- 支持多种不同的compaction策略
RocksDB 子模块
RocksDB 5大子模块,分别为:
- Basic Operation,基本操作定义
- Terminology,内部术语定义
- Tool,内部工具
- Logging/Monitoring ,日志和监控
- System Behavior,内部系统行为
Basic Operation
除了 RocksDB 核心的KV的操作接口get,put两类操作外,RocksDB 还在此模块中封装了如下几类能适用于特殊使用场景的操作:
Iteration,Rocks DB能够支持区间范围内的key迭代器的遍历查找。
Compaction Filter,用户可使用 Compaction Filter 对 key 值进行删除或其它更新操作的逻辑定义,当系统进行 Compact 行为的时候。
Creating and Ingesting SST files,当用户想要快速导入大批量数据到系统内时,可以通过线下创建有效格式的 SST 文件并导入的方式,而非使用 API 进行 KV 值的单独PUT操作。
Delete Range,区间范围的删除操作,比一个个 Key 的单独删除调用使用更方便。
Low Priority Write,当用户执行大批量数据 load 的操作时但担心可能会影响到系统正常的操作处理时,可以开启此属性进行优先级的调整。
Read-Modify-Write,这个操作的实际含义是 Merge 操作的含义,读取现有键值,进行更新(累加计数或依赖原有值的任何更新操作),将新的值写入到原 Key 下。 如果使用原始 Get/Set API 的前提下,我们要调用2次 Get 1次,然后再 Set 1次,在 Merge API 下,使用者调用1次就足够了。
Transaction,RocksDB 内部提供乐观式的 OptimisticTransactionDB 和悲观式(事务锁方式)的 TransactionDB 来支持并发的键值更新操作。
Terminology
首先是RocksDB内部的相关术语定义说明,如上图所示,主要有以下一些术语:
Write-Ahead-Log File,类似于HDFS JournalNode中的editlog,用于记录那些未被成功提交的数据操作,然后在重启时进行数据的恢复。 SST File,SST文件是一段排序好的表文件,它是实际持久化的数据文件。里面的数据按照key进行排序能方便对其进行二分查找。在SST文件内,还额外包含以下特殊信息: Bloom Fileter,用于快速判断目标查询key是否存在于当前SST文件内。 Index / Partition Index,SST内部数据块索引文件快速找到数据块的位置。 Memtable,内存数据结构,用以存储最近更新的db更新操作,memtable空间写满后,会触发一次写出更新操作到SST文件的操作。 Block Cache,纯内存存储结构,存储SST文件被经常访问的热点数据。
System Behavior
在RocksDB内部,有着许多系统操作行为来保障系统的平稳运行。
Compression,SST文件内的数据能够被压缩存储来减小占用空间。 Rate Limit行为。用户能够对其写操作进行速度控制,以此避免写入速度过快造成系统读延迟的现象。 Delete Schedule,系统文件删除行为的速度控制。 Direct IO,RocksDB支持绕过系统Page Cache,通过应用内存从存储设置中直接进行IO读写操作。 Compaction,数据的Compact行为,删除SST文件中重复的key以及过期的key数据。
Logging/Monitoring
RocksDB内部有以下的日志监控工具: Logger,可用的Logger使用类。 Statistic / Perf Context and IO Stats Context,RocksDB内部各类型操作的时间,操作数计数统计信息,此数据信息能被用户用来发现系统的性能瓶颈操作。 EventListener,此监听接口提供了一些event事件发生后的接口回调,比如完成一次flush操作,开始Compact操作的时候等等。
结合官方Example分析代码
int main() {
DB* db;
Options options;
// 优化 Rocksdb 的配置
options.IncreaseParallelism();
options.OptimizeLevelStyleCompaction();
options.create_if_missing = true;
// 打开数据库
Status s = DB::Open(options, kDBPath, &db);
assert(s.ok());
// 操作数据库
s = db->Put(WriteOptions(), "key1", "value");
assert(s.ok());
std::string value;
s = db->Get(ReadOptions(), "key1", &value);
assert(s.ok());
assert(value == "value");
// 原子化操作数据库
{
WriteBatch batch;
batch.Delete("key1");
batch.Put("key2", value);
s = db->Write(WriteOptions(), &batch);
}
s = db->Get(ReadOptions(), "key1", &value);
assert(s.IsNotFound());
db->Get(ReadOptions(), "key2", &value);
assert(value == "value");
// 使用 PinnableSlice 减少拷贝
{
PinnableSlice pinnable_val;
db->Get(ReadOptions(), db->DefaultColumnFamily(), "key2", &pinnable_val);
assert(pinnable_val == "value");
}
{
std::string string_val;
PinnableSlice pinnable_val(&string_val);
db->Get(ReadOptions(), db->DefaultColumnFamily(), "key2", &pinnable_val);
assert(pinnable_val == "value");
assert(pinnable_val.IsPinned() || string_val == "value");
}
PinnableSlice pinnable_val;
s = db->Get(ReadOptions(), db->DefaultColumnFamily(), "key1", &pinnable_val);
assert(s.IsNotFound());
pinnable_val.Reset();
db->Get(ReadOptions(), db->DefaultColumnFamily(), "key2", &pinnable_val);
assert(pinnable_val == "value");
pinnable_val.Reset();
delete db;
return 0;
}
更多技术分享浏览我的博客:
https://thierryzhou.github.io