Kubernetes 调度器详解
概览
在 Kubernetes 中,调度 (scheduling) 指的是确保 Pod 匹配到合适的节点, 以便 kubelet 能够运行它们。 调度的工作由调度器和控制器协调完成。
调度器通过 Kubernetes 的监测(Watch)机制来发现集群中新创建且尚未被调度到节点上的 Pod。 调度器会将所发现的每一个未调度的 Pod 调度到一个合适的节点上来运行。 调度器会依据下文的调度原则来做出调度选择。控制器则会将调度写入 Kubernetes 的API Server中。
kube-scheduler
kube-scheduler 是 Kubernetes 集群的默认调度器,并且是集群 控制面 的一部分。对每一个新创建的 Pod 或者是未被调度的 Pod,kube-scheduler 会选择一个最优的节点去运行这个 Pod。
在一个集群中,满足一个 Pod 调度请求的所有节点称之为 可调度节点。 如果没有任何一个节点能满足 Pod 的资源请求, 那么这个 Pod 将一直停留在未调度状态直到调度器能够找到合适的 Node。
调度器先在集群中找到一个 Pod 的所有可调度节点,然后根据一系列函数对这些可调度节点打分, 选出其中得分最高的节点来运行 Pod。之后,调度器将这个调度决定通知给 kube-apiserver,这个过程叫做 绑定(bind)。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、 亲和以及反亲和要求、数据局部性、负载间的干扰等等。
kube-scheduler 调度流程
kube-scheduler 给一个 Pod 做调度选择时包含两个步骤:
- 过滤(Filtering)
- 打分(Scoring)
Pod 内的每一个容器对资源都有不同的需求, 而且 Pod 本身也有不同的需求。因此,Pod 在被调度到节点上之前, 根据这些特定的调度需求,需要对集群中的节点进行一次过滤。
过滤阶段会将所有满足 Pod 调度需求的节点选出来。例如, PodFitsResources 过滤函数会检查候选节点的可用资源能否满足 Pod 的资源请求。 在过滤之后,得出一个节点列表,里面包含了所有可调度节点;通常情况下, 这个节点列表包含不止一个节点。如果这个列表是空的,代表这个 Pod 不可调度。
在打分阶段,调度器会为 Pod 从所有可调度节点中选取一个最合适的节点。 根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。最后, kube-scheduler 会将 Pod 调度到得分最高的节点上。 如果存在多个得分最高的节点, kube-scheduler 会从中随机选取一个。
你可以通过修改配置文件 (KubeSchedulerConfiguration) 中的调度策略 (Scheduling Policies) 和调度配置 (Scheduling Profiles) ,可以定义自己的配置调度器的过滤和打分行为。调度策略(Scheduling Policies) 允许你配置过滤所用的 断言 (Predicates) 和打分所用的 优先级 (Priorities);调度配置(Scheduling Profiles)允许你配置实现不同调度阶段的插件,包括:QueueSort、Filter、Score、Bind、Reserve、Permit 等等。
调度框架(framework)
Kubernetes 调度器中大多数的调度功能,通过调度框架 (framework) 这一插件架构中一个一个具体的调度插件实现。它通过向现有的调度器添加了一组新的“插件” API,编译过程中插件编与调度器打包。
调度框架 (framework) 定义了一些扩展点。调度器插件注册后在一个或多个扩展点处被调用。 这些插件中的一些可以改变调度决策,而另一些仅用于提供信息。
每次调度一个 Pod 的尝试都分为两个阶段,调度周期和绑定周期。
调度周期为 Pod 选择一个节点,绑定周期将该决策应用于集群。 调度周期和绑定周期一起被称为“调度上下文”。
调度周期是串行运行的,而绑定周期可能是同时运行的。
如果确定 Pod 不可调度或者存在内部错误,则可以终止调度周期或绑定周期。 Pod 将返回队列并重试。
下图显示了一个 Pod 的调度上下文以及调度框架公开的扩展点。 在此图片中,“过滤器”等同于“断言”,“评分”相当于“优先级函数”。
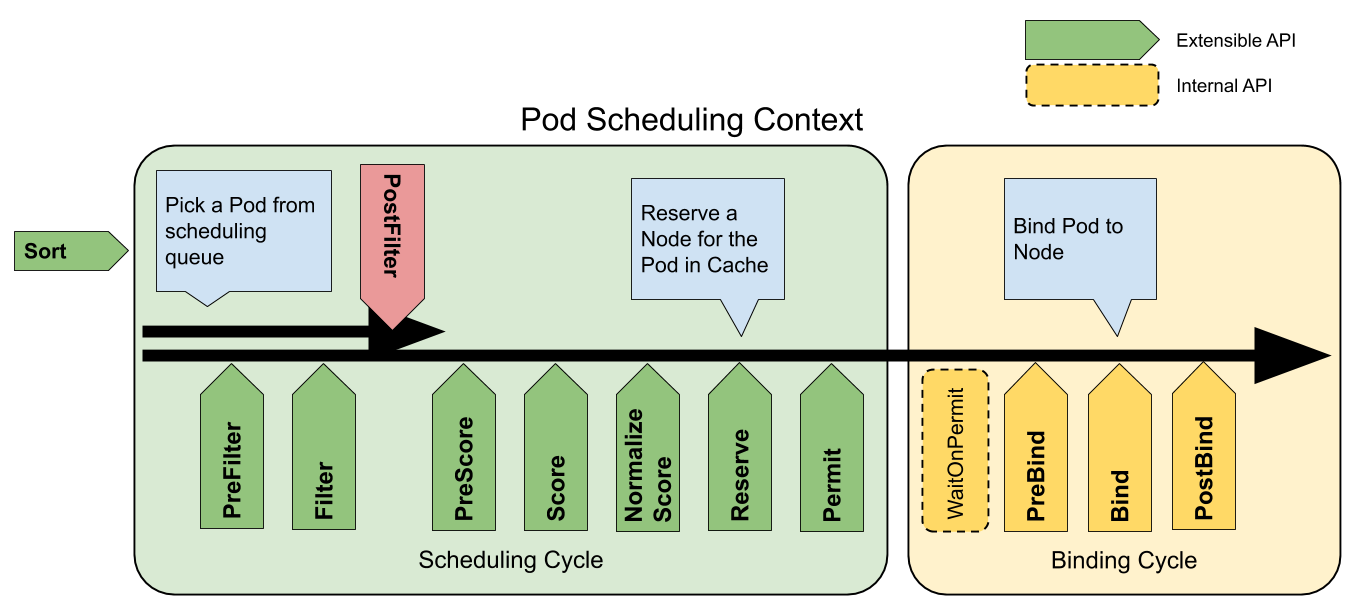
一个插件可以在多个扩展点处注册,以执行更复杂或有状态的任务。
调度框架扩展点
-
Sort 这些插件用于对调度队列中的 Pod 进行排序。 队列排序插件本质上提供 less(Pod1, Pod2) 函数。 一次只能启动一个队列插件。
-
PreFilter 这些插件用于预处理 Pod 的相关信息,或者检查集群或 Pod 必须满足的某些条件。 如果 PreFilter 插件返回错误,则调度周期将终止。
-
Filter 这些插件用于过滤出不能运行该 Pod 的节点。对于每个节点, 调度器将按照其配置顺序调用这些过滤插件。如果任何过滤插件将节点标记为不可行, 则不会为该节点调用剩下的过滤插件。节点可以被同时进行评估。
-
PostFilter 这些插件在 Filter 阶段后调用,但仅在该 Pod 没有可行的节点时调用。 插件按其配置的顺序调用。如果任何 PostFilter 插件标记节点为“Schedulable”, 则其余的插件不会调用。典型的 PostFilter 实现是抢占,试图通过抢占其他 Pod 的资源使该 Pod 可以调度。
-
PreScore 这些插件用于执行 “前置评分(pre-scoring)” 工作,即生成一个可共享状态供 Score 插件使用。 如果 PreScore 插件返回错误,则调度周期将终止。
-
Score 这些插件用于对通过过滤阶段的节点进行排序。调度器将为每个节点调用每个评分插件。 将有一个定义明确的整数范围,代表最小和最大分数。 在标准化评分阶段之后,调度器将根据配置的插件权重 合并所有插件的节点分数。
-
NormalizeScore 这些插件用于在调度器计算 Node 排名之前修改分数。 在此扩展点注册的插件被调用时会使用同一插件的 Score 结果。 每个插件在每个调度周期调用一次。
例如,假设一个 BlinkingLightScorer 插件基于具有的闪烁指示灯数量来对节点进行排名。
func ScoreNode(_ *v1.pod, n *v1.Node) (int, error) {
return getBlinkingLightCount(n)
}
然而,最大的闪烁灯个数值可能比 NodeScoreMax 小。要解决这个问题, BlinkingLightScorer 插件还应该注册该扩展点。
func NormalizeScores(scores map[string]int) {
highest := 0
for _, score := range scores {
highest = max(highest, score)
}
for node, score := range scores {
scores[node] = score*NodeScoreMax/highest
}
}
如果任何 NormalizeScore 插件返回错误,则调度阶段将终止。
说明: 希望执行“预保留”工作的插件应该使用 NormalizeScore 扩展点。
- Reserve Reserve 是一个信息性的扩展点。 管理运行时状态的插件(也成为“有状态插件”)应该使用此扩展点,以便 调度器在节点给指定 Pod 预留了资源时能够通知该插件。 这是在调度器真正将 Pod 绑定到节点之前发生的,并且它存在是为了防止 在调度器等待绑定成功时发生竞争情况。
这个是调度周期的最后一步。 一旦 Pod 处于保留状态,它将在绑定周期结束时触发 Unreserve 插件 (失败时)或 PostBind 插件(成功时)。
- Permit Permit 插件在每个 Pod 调度周期的最后调用,用于防止或延迟 Pod 的绑定。 一个允许插件可以做以下三件事之一: 批准 一旦所有 Permit 插件批准 Pod 后,该 Pod 将被发送以进行绑定。 拒绝 如果任何 Permit 插件拒绝 Pod,则该 Pod 将被返回到调度队列。 这将触发Unreserve 插件。 等待(带有超时) 如果一个 Permit 插件返回 “等待” 结果,则 Pod 将保持在一个内部的 “等待中” 的 Pod 列表,同时该 Pod 的绑定周期启动时即直接阻塞直到得到 批准。如果超时发生,等待 变成 拒绝,并且 Pod 将返回调度队列,从而触发 Unreserve 插件。 说明: 尽管任何插件可以访问 “等待中” 状态的 Pod 列表并批准它们 (查看 FrameworkHandle)。 我们期望只有允许插件可以批准处于 “等待中” 状态的预留 Pod 的绑定。 一旦 Pod 被批准了,它将发送到 PreBind 阶段。
- PreBind 这些插件用于执行 Pod 绑定前所需的所有工作。 例如,一个 PreBind 插件可能需要制备网络卷并且在允许 Pod 运行在该节点之前 将其挂载到目标节点上。
如果任何 PreBind 插件返回错误,则 Pod 将被 拒绝 并且 退回到调度队列中。
-
Bind Bind 插件用于将 Pod 绑定到节点上。直到所有的 PreBind 插件都完成,Bind 插件才会被调用。 各 Bind 插件按照配置顺序被调用。Bind 插件可以选择是否处理指定的 Pod。 如果某 Bind 插件选择处理某 Pod,剩余的 Bind 插件将被跳过。
-
PostBind 这是个信息性的扩展点。 PostBind 插件在 Pod 成功绑定后被调用。这是绑定周期的结尾,可用于清理相关的资源。
-
Unreserve 这是个信息性的扩展点。 如果 Pod 被保留,然后在后面的阶段中被拒绝,则 Unreserve 插件将被通知。 Unreserve 插件应该清楚保留 Pod 的相关状态。
使用此扩展点的插件通常也使用 Reserve。
如何实现一个自定义的插件 API?
插件 API 分为两个步骤。首先,插件必须完成注册并配置,然后才能使用扩展点接口。 扩展点接口具有以下形式。
type Plugin interface {
Name() string
}
type QueueSortPlugin interface {
Plugin
Less(*v1.pod, *v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter(context.Context, *framework.CycleState, *v1.pod) error
}
// ...
下面分析一下 kube-scheduler 中自带的 nodeports 插件的代码,该插件负责筛选 Pod 所需端口还未被占用的节点。这里只贴一下 nodeports.go 文件中的代码, PreFilter 和 Filter 插件在kube-scheduler被调用的代码有兴趣的小伙伴可以自己去扒一下。
// kubernetes/pkg/scheduler/framework/plugins/nodeports/nodeports.go
package nodeports
import (
"context"
"fmt"
v1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/kubernetes/pkg/scheduler/framework"
"k8s.io/kubernetes/pkg/scheduler/framework/plugins/names"
)
type NodePorts struct{}
// 实现了NodePorts结构实现了 framework.PreFilterPlugin、framework.FilterPlugin、framework.EnqueueExtensions三个接口
var _ framework.PreFilterPlugin = &NodePorts{}
var _ framework.FilterPlugin = &NodePorts{}
var _ framework.EnqueueExtensions = &NodePorts{}
const (
Name = names.NodePorts
// 将插件名放入preFilterStateKey 防止与其他插件命名冲突
preFilterStateKey = "PreFilter" + Name
// 错误提示
ErrReason = "node(s) didn't have free ports for the requested pod ports"
)
type preFilterState []*v1.ContainerPort
// 复制 prefilter 的状态.
func (s preFilterState) Clone() framework.StateData {
// The state is not impacted by adding/removing existing pods, hence we don't need to make a deep copy.
return s
}
// Name函数返回插件名
func (pl *NodePorts) Name() string {
return Name
}
// 查询并返回所有 Pods 中用到的端口
func getContainerPorts(pods ...*v1.Pod) []*v1.ContainerPort {
ports := []*v1.ContainerPort{}
for _, pod := range pods {
for j := range pod.Spec.Containers {
container := &pod.Spec.Containers[j]
for k := range container.Ports {
ports = append(ports, &container.Ports[k])
}
}
}
return ports
}
// PreFilter 扩展点
func (pl *NodePorts) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
s := getContainerPorts(pod)
cycleState.Write(preFilterStateKey, preFilterState(s))
return nil, nil
}
// 未定义 PreFilterExtensions 扩展点
func (pl *NodePorts) PreFilterExtensions() framework.PreFilterExtensions {
return nil
}
func getPreFilterState(cycleState *framework.CycleState) (preFilterState, error) {
c, err := cycleState.Read(preFilterStateKey)
if err != nil {
// 如果 cycleState 中 preFilterState 不存在, 很有可能是因为 PreFilter 还未被调用
return nil, fmt.Errorf("reading %q from cycleState: %w", preFilterStateKey, err)
}
s, ok := c.(preFilterState)
if !ok {
return nil, fmt.Errorf("%+v convert to nodeports.preFilterState error", c)
}
return s, nil
}
// 反馈 一个 Pod 调度失败可能的错误原因
func (pl *NodePorts) EventsToRegister() []framework.ClusterEvent {
return []framework.ClusterEvent{
// Due to immutable fields `spec.containers[*].ports`, pod update events are ignored.
{Resource: framework.Pod, ActionType: framework.Delete},
{Resource: framework.Node, ActionType: framework.Add | framework.Update},
}
}
// Filter 扩展点
func (pl *NodePorts) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
wantPorts, err := getPreFilterState(cycleState)
if err != nil {
return framework.AsStatus(err)
}
fits := fitsPorts(wantPorts, nodeInfo)
if !fits {
return framework.NewStatus(framework.Unschedulable, ErrReason)
}
return nil
}
// 检查 Pod 是否能被调度到节点上(端口是否被占用)
func Fits(pod *v1.Pod, nodeInfo *framework.NodeInfo) bool {
return fitsPorts(getContainerPorts(pod), nodeInfo)
}
func fitsPorts(wantPorts []*v1.ContainerPort, nodeInfo *framework.NodeInfo) bool {
// existingPorts 和 wantPorts 存在冲突,则节点不适合被调度
existingPorts := nodeInfo.UsedPorts
for _, cp := range wantPorts {
if existingPorts.CheckConflict(cp.HostIP, string(cp.Protocol), cp.HostPort) {
return false
}
}
return true
}
// 插件初始化
func New(_ runtime.Object, _ framework.Handle) (framework.Plugin, error) {
return &NodePorts{}, nil
}
你可以在调度器配置中启用或禁用插件。 如果你在使用 Kubernetes v1.18 或更高版本,大部分调度插件都在使用中且默认启用。
kube-scheduler 主流程分析
kube-scheduler的主流程如下图, kube-scheduler 初始化一个 informer 队列,存放未调度的 pod ;初始化一个 informer 缓存队列,存放拥有调度中间状态的pod、node等对象。实际执行调度任务的是sched.scheduleOne方法,它每次从未调度队列中娶取出一个 Pod ,经过预选与优选算法,最终选出一个最优 node ,上述步骤都成功则更新缓存队列并异步执行 bind 操作,也就是更新 pod 的 nodeName 字段,失败则进入抢占逻辑,至此一个 pod 的调度工作完成。
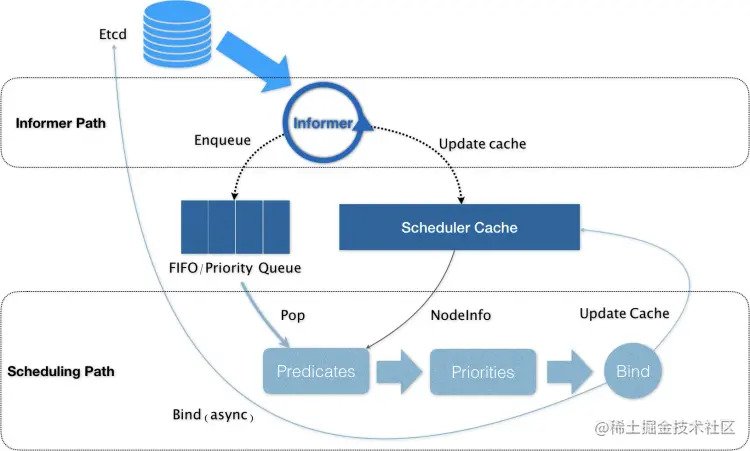
看一下 kube-scheduler 入口函数的代码:
// kubernetes/cmd/kube-scheduler/app/server.go
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
klog.InfoS("Starting Kubernetes Scheduler", "version", version.Get())
klog.InfoS("Golang settings", "GOGC", os.Getenv("GOGC"), "GOMAXPROCS", os.Getenv("GOMAXPROCS"), "GOTRACEBACK", os.Getenv("GOTRACEBACK"))
if cz, err := configz.New("componentconfig"); err == nil {
cz.Set(cc.ComponentConfig)
} else {
return fmt.Errorf("unable to register configz: %s", err)
}
// 启动事件处理流程
cc.EventBroadcaster.StartRecordingToSink(ctx.Done())
defer cc.EventBroadcaster.Shutdown()
// 启动健康检查
var checks []healthz.HealthChecker
if cc.ComponentConfig.LeaderElection.LeaderElect {
checks = append(checks, cc.LeaderElection.WatchDog)
}
waitingForLeader := make(chan struct{})
isLeader := func() bool {
select {
case _, ok := <-waitingForLeader:
// if channel is closed, we are leading
return !ok
default:
// channel is open, we are waiting for a leader
return false
}
}
// 启动健康检查服务
if cc.SecureServing != nil {
handler := buildHandlerChain(newHealthzAndMetricsHandler(&cc.ComponentConfig, cc.InformerFactory, isLeader, checks...), cc.Authentication.Authenticator, cc.Authorization.Authorizer)
// TODO: handle stoppedCh and listenerStoppedCh returned by c.SecureServing.Serve
if _, _, err := cc.SecureServing.Serve(handler, 0, ctx.Done()); err != nil {
// fail early for secure handlers, removing the old error loop from above
return fmt.Errorf("failed to start secure server: %v", err)
}
}
// 启动所有Informer
cc.InformerFactory.Start(ctx.Done())
if cc.DynInformerFactory != nil {
cc.DynInformerFactory.Start(ctx.Done())
}
// 等待调度完成后,更新缓存队列
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// DynInformerFactory can be nil in tests.
if cc.DynInformerFactory != nil {
cc.DynInformerFactory.WaitForCacheSync(ctx.Done())
}
// 如果开启了选主选,则进入选主流程。选主结束后开始 Pod 调度
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
close(waitingForLeader)
sched.Run(ctx)
},
OnStoppedLeading: func() {
select {
case <-ctx.Done():
klog.InfoS("Requested to terminate, exiting")
os.Exit(0)
default:
klog.ErrorS(nil, "Leaderelection lost")
klog.FlushAndExit(klog.ExitFlushTimeout, 1)
}
},
}
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
// 没有开启选主,则直接进入 Pod 调度流程。
close(waitingForLeader)
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
调度器会先执行schedule函数,从未调度队列中取出一个 Pod 后,带着这个 Pod 的相关信息进入 scheduleOne 函数开始对这个 Pod 进行调度:
// kubernetes/pkg/scheduler/schedule_one.go
func (sched *Scheduler) scheduleOne(ctx context.Context) {
podInfo := sched.NextPod()
// 没有找到一下一个 Pod 时,结束本次调度
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
klog.ErrorS(err, "Error occurred")
return
}
if sched.skipPodSchedule(fwk, pod) {
return
}
klog.V(3).InfoS("Attempting to schedule pod", "pod", klog.KObj(pod))
// Synchronously attempt to find a fit for the pod.
start := time.Now()
state := framework.NewCycleState()
state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)
// Initialize an empty podsToActivate struct, which will be filled up by plugins or stay empty.
podsToActivate := framework.NewPodsToActivate()
state.Write(framework.PodsToActivateKey, podsToActivate)
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
scheduleResult, assumedPodInfo := sched.schedulingCycle(schedulingCycleCtx, state, fwk, podInfo, podsToActivate, start)
if scheduleResult.FeasibleNodes == 0 {
return
}
// 异步执行 Pod Bind 任务
go func() {
bindingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Inc()
defer metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Dec()
metrics.Goroutines.WithLabelValues(metrics.Binding).Inc()
defer metrics.Goroutines.WithLabelValues(metrics.Binding).Dec()
sched.bindingCycle(bindingCycleCtx, state, fwk, scheduleResult, assumedPodInfo, podsToActivate, start)
}()
}
schedulingCycle 中封装了整个调度过程的逻辑主体,调度框架的插件扩展点函数大多数在这里被调度器调度,下面看 chedulingCycle 函数的代码:
func (sched *Scheduler) schedulingCycle(ctx context.Context, state *framework.CycleState, fwk framework.Framework, podInfo *framework.QueuedPodInfo, podsToActivate *framework.PodsToActivate, start time.Time) (ScheduleResult, *framework.QueuedPodInfo) {
pod := podInfo.Pod
scheduleResult, err := sched.SchedulePod(ctx, fwk, state, pod)
if err != nil {
// 如果调取器无法为 Pod 分配一个适合调度的节点, 则尝试进入抢占逻辑,
// 抢占逻辑试图找到一个节点, 在该节点中删除一个或多个优先级较低的 Pod,如果找到这样的节点,这些优先级较低的 Pod 会被从节点中驱逐。
var nominatingInfo *framework.NominatingInfo
reason := v1.PodReasonUnschedulable
if fitError, ok := err.(*framework.FitError); ok {
if !fwk.HasPostFilterPlugins() {
klog.V(3).InfoS("No PostFilter plugins are registered, so no preemption will be performed")
} else {
// 调用 PostFilter 插件
result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)
if status.Code() == framework.Error {
klog.ErrorS(nil, "Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
} else {
fitError.Diagnosis.PostFilterMsg = status.Message()
klog.V(5).InfoS("Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
}
if result != nil {
nominatingInfo = result.NominatingInfo
}
}
// Pod did not fit anywhere, so it is counted as a failure. If preemption
// succeeds, the pod should get counted as a success the next time we try to
// schedule it. (hopefully)
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
} else if err == ErrNoNodesAvailable {
nominatingInfo = clearNominatedNode
// No nodes available is counted as unschedulable rather than an error.
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
} else {
nominatingInfo = clearNominatedNode
klog.ErrorS(err, "Error selecting node for pod", "pod", klog.KObj(pod))
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = v1.PodReasonSchedulerError
}
sched.FailureHandler(ctx, fwk, podInfo, err, reason, nominatingInfo)
return ScheduleResult{}, nil
}
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInSeconds(start))
// 为了让我们不用等待 binding 事件完成,先将调度完成的状态写入缓存队列中
assumedPodInfo := podInfo.DeepCopy()
assumedPod := assumedPodInfo.Pod
// assume modifies `assumedPod` by setting NodeName=scheduleResult.SuggestedHost
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
if err != nil {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// 返回错误
sched.FailureHandler(ctx, fwk, assumedPodInfo, err, v1.PodReasonSchedulerError, clearNominatedNode)
return ScheduleResult{}, nil
}
// 调用 reserve 插件
if sts := fwk.RunReservePluginsReserve(ctx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// trigger un-reserve to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "Scheduler cache ForgetPod failed")
}
sched.FailureHandler(ctx, fwk, assumedPodInfo, sts.AsError(), v1.PodReasonSchedulerError, clearNominatedNode)
return ScheduleResult{}, nil
}
// 调用 permit 插件
runPermitStatus := fwk.RunPermitPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if !runPermitStatus.IsWait() && !runPermitStatus.IsSuccess() {
var reason string
if runPermitStatus.IsUnschedulable() {
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = v1.PodReasonUnschedulable
} else {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = v1.PodReasonSchedulerError
}
// One of the plugins returned status different from success or wait.
fwk.RunReservePluginsUnreserve(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "Scheduler cache ForgetPod failed")
}
sched.FailureHandler(ctx, fwk, assumedPodInfo, runPermitStatus.AsError(), reason, clearNominatedNode)
return ScheduleResult{}, nil
}
// 完成调度
if len(podsToActivate.Map) != 0 {
sched.SchedulingQueue.Activate(podsToActivate.Map)
// Clear the entries after activation.
podsToActivate.Map = make(map[string]*v1.Pod)
}
return scheduleResult, assumedPodInfo
}
调度器配置文件
在配置文件中,对每个扩展点,你可以禁用默认插件或者是启用自己的插件,例如:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- plugins:
score:
disabled:
- name: PodTopologySpread
enabled:
- name: MyCustomPluginA
weight: 2
- name: MyCustomPluginB
weight: 1
更多技术分享浏览我的博客:
https://thierryzhou.github.io
参考
- [1] [kubenretes官方文档——概述——调度] (https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/)
- [2] [kubenretes官方文档——调度] (https://kubernetes.io/zh-cn/docs/reference/scheduling/)