Kubrenetes API Server详解
没时间整理,列一些知识点在这里,以后整理。
概述
kube-apiserver 提供集群管理的REST API接口,包括认证授权、数据校验以及集群状态变更等。它是其他模块之间的数据交互和通信的枢纽(其他模块通过 APIServer 查询或修改数据,只有API Server 才直接操作 etcd)。
在 kubernetes 集群中,应该只有 apiserver 自己去连 etcd ,因为apiserver这边可以对etcd做些保护操作,比如限流的操作,认证鉴权的操作,它是挡在etcd之前的一个守护者,apiserver这边又有缓存的机制,其实很多的读操作就在apiserver这边处理掉了,它不会再将请求转到etcd里面去,这样的话其实有效的减少了整个集群对etcd的并发请求。
架构
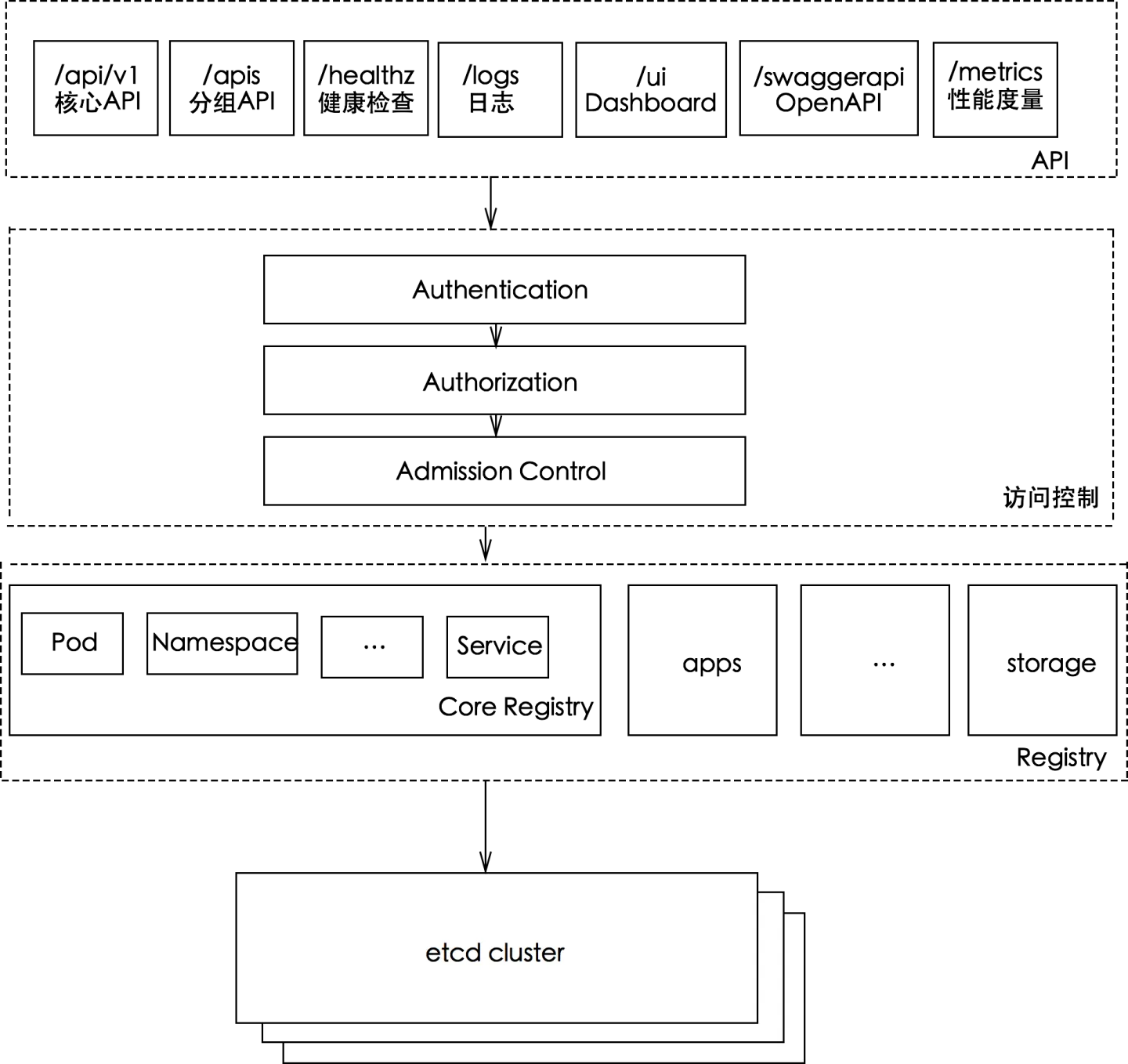
访问控制概览
Kubernetes API的每个请求都会经过多阶段的访问控制之后才会被接受,这包括认证、授权以及准入控制(Admission Control)等。
从apiserver接收到请求,到数据存储到数据库,中间经历了哪些流转。
request发送到apiserver,首先最开始有HTTP handle,这个handle接收到这个请求之后,请求会被发送到认证鉴权两个模块,认证其实就是就是api网关最基础的能力,我要知道你是谁,这里提供了一系列的认证手段。
鉴权:我知道的你是谁之后,然后要知道你有没有操作权限。
认证鉴权之后,比如说某个请求属性没有设置,我希望给你一个默认值,或者修改你的属性值。这个时候我希望在apiserver端对你的request增加一些属性,这个对方就会走mutating,所谓的mutating就是变形,它是支持webhook的,除了kubernetes自身可以对你这个数据做一些修改,你还可以通过一些webhook来针对这些对象做一些修改。
mutating做完之后,就走入了k8s自定义的这些对象的schema validation,由于之前做过变形,我要去看变形之后的对象是不是合法的,是不是符合kubermetes的规范。
做完上面的之后,如果你还要去做一些附加的校验,比如说k8s规定的名字不能超过255,但是我希望名字在我自己的生产环境里面不超过63,那么你就可以附加一些最强的validation在webhook里面,通过validating admission plugin来调用你的webhook,把你的校验逻辑加上去。
最后所有的这些流转做完了之后,整个数据才会存放到etcd里面去,到此位置,数据的持久化就做完了。
访问控制细节
panic recovery
apiserver在收到请求之后,进来之后是panic recovery,因为apiserver相对于一个服务器,它会启动不同的goroutine来处理不同的请求,当这些请求出现panic的时候,这时候就要确保某个goroutine panic不会将整个http server搞死,所以这里就有panic recovery的机制。
request-timeout
之后就是设置request-timeout,request超时时间,假设后面的请求没有被及时的处理,那么request就失败了,如果不设置request超时时间就意味着客户端这个connection一直连接着的。
认证/审计
接下来做认证,认证完了就去做审计,这里面会去记录谁对哪些对象做了哪些操作,所以审计很多时候是有效的,比如是平台的维护方,上面跑了很多的应用,很多时候经常有用户跑过来说为什么跑在你集群上面的对象我的业务无缘无故就消失了,肯定是你们做了什么操作,这个时候查auditlog,几乎百分之百就是客户自己删除的,因为作为运营方不会去碰用户的业务。
impersonation:它是一个request发送到http server这一端的时候,你可以为这个request加上header,这些header可以模拟这个request给谁用,request代表哪个用户,现在用的不太广泛。
在以前集群联邦的层面,我从联邦集群发下来的request,集群联邦连每一个member cluster的时候用的是root的kubeconfig,但是集群联邦的层面是代用户去分发这些request,通过impersonation我们就会将用户的真实的信息填在这个request里面,那么这个request发到集群下面的话,那么api server就会去读impersonation的信息来判断request是谁的,以此来做权限的校验,来判断用户有没有这个对象的操作权限。
限流
max-in-flight是原来做限流的,也就是apiserver里面能够最多处理多少个请求,如果超过就拒绝。
所谓的inflight就是在路上的请求,就是从request放到apiserver端到request还没返回客户端,这中间是有一个时间周期,也就是在这个时间周期在APIserver这边会有很多request是在被处理的过程中, max-in-flight也就是当前多少request在路上,如果到达了上限,还有新的request发过来,那么到这里面就拒绝了。
鉴权
限流之后完了就去做鉴权,鉴权去判断你有没有这个操作权限。
Aggregator/CRD
然后接下来会有一个比较重要的组件,kube-aggregator,因为apiserver本身是http处理器,它可以将request转走,在这里面aggregate就会判断说现在的request是不是标准的k8s对象,如果是,那么默认的apiserver就处理掉了,但是你想做扩展,比如说你自定义的k8s一些对象,然后你有另外的apiserver来支撑这些新对象,那么你就可以在这里面做些配置,k8s会去判断好像有些请求不是k8s内定的,通过读取配置将你的request转到其他地方,那么它就会将request发到aggregate apiserver,也就是它本身是一个代理了,有些请求就转出去了,没有转出去的request会被本地处理。
Conversion
到本地这里,之前的request都是json,这里面就要去做decoding,就是将这个对象给它反序列化,反序列化就变成了go的一个个对象了,这里需要做一个conversion,也即是将外部的结构转化为内部的结构,k8s任何的对象都有external version和internal version,external version是面向用户的,internal version是面向自己的实现,然后他就将对象转化为internal version,你可以理解将internal version存在了etcd里面。
Admission
先去做转换conversion,然后去做admission,admission就是有几个步骤,先去看有没有mutating webhook,有就调用,如果没有就走内置的validating这个流程,那么内置的validating k8s自己对象里面会去实现,比如对pod来说做哪些校验规则,它会去调用这些方法来校验这个pod是不是合法的,比如容器的image没有提供,那么这里面肯定是不过的。
做完内置的validating你想做附加的validating那么它就去看看你没有附加的validating webhook,如果有的话就去调用。
上面这些都通过了就存入到etcd,etcd存完了之后就返回客户端。
API 组织结构
话说自己入坑云原生也有好几年了,但是对 kubernetes 基础认识却不够深,导致写代码的时候经常需要打开 godoc 或者 kubernetes 源码查看某个接口或者方法的定义。这种快餐式的消费代码方式可以解决常见的问题,但有时候却会被一个简单的问题困扰很久。究其原因,还是没有对 kubernetes 有比较系统的学习,特别对于 kubernetes API 的设计与原理没有较为深入的认识,这也是我们平时扩展 kubernetes 功能绕不开的话题。与此同时,这也是很难讲清楚的一个话题,是因为 kubernetes 经过多个版本的迭代功能已经趋于成熟与复杂,这一点也可以从 Github 平台 kubernetes 组织下的多个仓库也可以看得出来,相信很多人和我一样,看到 kubernetes、client-go、api、apimachinery 等仓库就不知道如何下手。事实上,从 API 入手是比较简单的做法,特别是我们对于 kubernetes 核心组件的功能有了一定的了解之后。
接下来的几篇笔记,我将由浅入深地学习 kubernetes API 的设计以及背后的原理。我的计划是这样的:
初识 kubernetes API 的组织结构
深入 kubernetes API 的源码实现
扩展 kubernetes API 的典型方式
废话不多说,我们先来认识一下 kubernetes API 的基础结构以及背后的设计原理。
API-Server 我们知道 kubernetes 控制层面的核心组件包括 API-Server、 Controller Manager、Scheduler,其中 API-Server 对内与分布式存储系统 etcd 交互实现 kubernetes 资源(例如 pod、namespace、configMap、service 等)的持久化,对外提供通过 RESTFul 的形式提供 kubernetes API[1] 的访问接口,除此之外,它还负责 API 请求的认证(authN)[2]、授权(authZ)[3]以及验证[4]。刚提到的“对外”是相对的概念,因为除了像 kubectl 之类的命令行工具之外,kubernetes 的其他组件也会通过各种客户端库来访问 kubernetes API,关于官方提供的各种客户端库请查看 client-libraries 列表[5],其中最典型的是 Go 语言的客户端库 client-go[6]。
API-Server 是 kubernetes 控制层面中唯一一个与 etcd 交互的组件,kubernetes 的其他组件都要通过 API-Server 来更新集群的状态,所以说 API-Server 是无状态的;当然也可以创建多个 API-Server 的实例来实现容灾。API-Server 通过配合 controller 模式来实现声明式的 API 管理 kubernetes 资源。
既然我们知道了 API-Server 的主要职责是提供 kubernetes 资源的 RESTFul API,那么客户端怎么去请求 kubernetes 资源, API-Server 怎么去组织这些 kubernetes 资源呢?
GVK vs GVR Kubernetes API 通过 HTTP 协议以 RESTful 的形式提供,API 资源的序列化方式主要是以 JSON 格式进行,但为了内部通信也支持 Protocol Buffer 格式。为了方便扩展与演进,kubernetes API 支持分组与多版本,这体现在不同的 API 访问路径上。有了分组与多版本支持,即使要在新版本中去掉 API 资源的特定字段或者重构 API 资源的展现形式,也可以保证版本之间的兼容性。
API-group 将整个 kubernetes API 资源分成各个组,可以带来很多好处:
各组可以单独打开或者关闭[7]
各组可以有独立的版本,在不影响其他组的情况下单独向前衍化
同一个资源可以同时存在于多个不同组中,这样就可以同时支持某个特定资源稳定版本与实验版本
关于 kubernetes API 资源的分组信息可以在序列化的资源定义中有所体现,例如:
其中 apiVersion 字段中 apps 即为 Deployment 资源的分组,实际上,Deployment 不止出现在 apps 分组里,也出现在 extensions 分组中,不同的分组可以实验不同的特性;另外,kubernetes 中的核心资源如 pod、namespace、configmap、node、service 等存在于 core 分组中,但是由于历史的原因,core 不出现在 apiVersion 字段中,例如以下定义一个 pod 资源的序列化对象:
API 分组也体现在访问资源的 RESTful API 路径上,core 组中的资源访问路径一般为 /api/$VERSION,其他命名组的资源访问路径则是 /apis/$GROUP_NAME/$VERSION,此外还有一些系统级别的资源,如集群指标信息 /metrics,以上这些就基本构成了 kubernetes API 的树结构:
API-version 为了支持独立的演进,kubernetes API 也支持不同的版本,不同的版本代表不同的成熟度。注意,这里说的是 API 而非资源支持多版本。因为多版本支持是针对 API 级别,而不是特定的资源或者资源的字段。一般来说,我们根据 API 分组、资源类型、namespace 以及 name 来区分不同的资源对象,对于同一个资源对象的不同版本,API-Server 负责不同版本之间的无损切换,这点对于客户端来说是完全透明的。事实上,不同版本的同类型的资源在持久化层的数据可能是相同的。例如,对于同一种资源类型支持 v1 和 v1beta1 两个 API 版本,以 v1beta1 版本创建该资源的对象,后续可以以v1 或者 v1beta1 来更新或者删除该资源对象。
API 多版本支持一般通过将资源分组置于不同的版本中来实现,例如,batch 同时存在 v2alph1 与 v1 版本。一般来说,新的资源分组先出现 v1alpha1 版本,随着稳定性的提高被推进到 v1beta1 ,最后从 v1 版本毕业。
随着新的用户场景出现,kubernetes API 需要不断变化,可能是新增一个字段,也可能是删除旧的字段,甚至是改变资源的展现形式。为了保证兼容性,kubernetes 制定了一系列的策略[8]。总的来说,对于已经 GA 的 API,API,kubernetes 严格维护其兼容性,终端用户可以放心食用,beta 版本的 API 则尽量维护,保证不打破版本跨版本之间的交互,而对于 alpha 版本的 API 则很难保证兼容性,不太推荐生产环境使用。
GVK 与 GVR 映射 在 kubernetes API 宇宙中,我们经常使用属于 GVK 或者 GVR 来区分特定的 kubernetes 资源。其中 GVK 是 Group Version Kind 的简称,而 GVR 则是 Group Version Resource 的简称。
通过上面对于 kubernetes API 分组和多版本的介绍中我们已经了解了 Group 与 Version,那么 Kind 与 Resource 又分别是指什么呢?
Kind 是 API “顶级”资源对象的类型,每个资源对象都需要 Kind 来区分它自身代表的资源类型,例如,对于一个 pod 的例子:
其中 kind 字段即代表该资源对象的类型。一般来说,在 kubernetes API 中有三种不同的 Kind:
单个资源对象的类型,最典型的就是刚才例子中提到的 Pod
资源对象的列表类型,例如 PodList 以及 NodeList 等
特殊类型以及非持久化操作的类型,很多这种类型的资源是 subresource, 例如用于绑定资源的 /binding、更新资源状态的 /status 以及读写资源实例数量的 /scale
需要注意的是,同 Kind 不止可以出现在同一分组的不同版本中,如 apps/v1beta1 与 apps/v1,它还可能出现在不同的分组中,例如 Deployment 开始以 alpha 的特性出现在 extensions 分组,GA 之后被推进到 apps 组,所以为了严格区分不同的 Kind,需要组合 API Group、API Version 与 Kind 成为 GVK。
Resource 则是通过 HTTP 协议以 JSON 格式发送或者读取的资源展现形式,可以以单个资源对象展现,例如 …/namespaces/default,也可以以列表的形式展现,例如 …/jobs。要正确的请求资源对象,API-Server 必须知道 apiVersion 与请求的资源,这样 API-Server 才能正确地解码请求信息,这些信息正是处于请求的资源路径中。一般来说,把 API Group、API Version 以及 Resource 组合成为 GVR 可以区分特定的资源请求路径,例如 /apis/batch/v1/jobs 就是请求所有的 jobs 信息。
GVR 常用于组合成 RESTful API 请求路径。例如,针对应用程序 v1 部署的 RESTful API 请求如下所示:
通过获取资源的 JSON 或 YAML 格式的序列化对象,进而从资源的类型信息中可以获得该资源的 GVK;相反,通过 GVK 信息则可以获取要读取的资源对象的 GVR,进而构建 RESTful API 请求获取对应的资源。这种 GVK 与 GVR 的映射叫做 RESTMapper。Kubernetes 定义了 RESTMapper 接口[9]并带默认带有实现 DefaultRESTMapper[10]。
关于 kubernetes API 的详细规范请参考 API Conventions[11]
如何储存 经过上一章节的研究,我们已经知道了 kubernetes API 的组织结构以及背后的设计原理,那么,Kubernetes API 的资源对象最终是怎么提供可靠存储的。之前也提到了 API-Server 是无状态的,它需要与分布式存储系统 etcd[12] 交互来实现资源对象的持久化操作。从概念上讲,etcd 支持的数据模型是键值(key-value)存储。在 etcd2 中,各个 key 是以层次结构存在,而在 etcd3 中这个就变成了平级模型,但为了保证兼容性也保持了层次结构的方式。
在 Kubernetes 中 etcd 是如何使用的呢?实际上,前面也提到了,etcd 被部署为独立的部分,甚至多个 etcd 可以组成集群,API-Server 负责与 etcd 交互来完成资源对象的持久化。从 1.5.x 之后,Kubernetes 开始全面使用 etcd3。可以在 API-Server 的相关启动项参数中配置使用 etcd 的方式:
Kubernetes 资源对象是以 JSON 或 Protocol Buffers 格式存储在 etcd 中,这可以通过配置 kube-apiserver 的启动参数 –storage-media-type 来决定想要序列化数据存入 etcd 的格式,默认情况下为 application/vnd.kubernetes.protobuf 格式;另外也可以通过配置 –storage-versions 启动参数来配置每个 API 分组的资源对象的持久化存储的默认版本号。
下面通过一个简单的例子来看,创建一个 pod,然后使用 etcdctl 工具来查看存储在 etcd 中数据:
使用各种客户端工具创建资源对象到然后存储到 etcd 的流程大致如下图所示:
客户端工具(例如 kubectl)提供一个期望状态的资源对象的序列化表示,该例子使用 YAML 格式提供
kubectl 将 YAML 转换为 JSON 格式,并发送给 API-Server
对应同类型对象的不同版本,API-Server 执行无损转换。对于老版本中不存在的字段则存储在 annotations 中
API-Server 将接收到的对象转换为规范存储版本,这个版本由 API-Server 启动参数指定,一般是最新的稳定版本
最后将资源对象通过 JSON 或 protobuf 方式解析并通过一个特定的 key 存入 etcd 当中
上面提到的无损转换是如何进行的?下面使用 Kubernetes 资源对象对象 Horizontal Pod Autoscaling (HPA) 来举例说明:
通过上面命令的输出能够看出,即使 HorizontalPodAutoscale 的版本从 v2beta1 变为了 v2beta2,API-Server 也能够在不同的版本之前无损转换,不论在 etcd 中实际存的是哪个版本。实际上,API-Server 将所有已知的 Kubernetes 资源类型保存在名为 Scheme 的注册表(registry)中。在此注册表中,定义了每种 Kubernetes 资源的类型、分组、版本以及如何转换它们,如何创建新对象,以及如何将对象编码和解码为 JSON 或 protobuf 格式的序列化形式。
list-watch
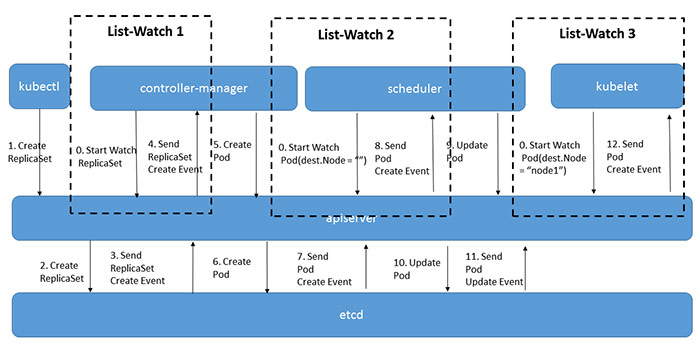
上图是一个典型的Pod创建过程,在这个过程中,每次当kubectl创建了ReplicaSet对象后,controller-manager都是通过list-watch这种方式得到了最新的ReplicaSet对象,并执行自己的逻辑来创建Pod对象。其他的几个组件,Scheduler/Kubelet也是一样,通过list-watch得知变化并进行处理。这是组件的处理端代码:
c.NodeLister.Store, c.nodePopulator = framework.NewInformer(
c.createNodeLW(),
&api.Node{},
0,
framework.ResourceEventHandlerFuncs{
AddFunc: c.addNodeToCache,
UpdateFunc: c.updateNodeInCache,
DeleteFunc: c.deleteNodeFromCache,
},
)
list-watch操作需要做这么几件事:
- 由组件向apiserver而不是etcd发起watch请求,在组件启动时就进行订阅,告诉apiserver需要知道什么数据发生变化。Watch是一个典型的发布-订阅模式。
- 组件向apiserver发起的watch请求是可以带条件的,例如,scheduler想要watch的是所有未被调度的Pod,也就是满足Pod.destNode=”“的Pod来进行调度操作;而kubelet只关心自己节点上的Pod列表。apiserver向etcd发起的watch是没有条件的,只能知道某个数据发生了变化或创建、删除,但不能过滤具体的值。也就是说对象数据的条件过滤必须在apiserver端而不是etcd端完成。
- list是watch失败,数据太过陈旧后的弥补手段,这方面详见 基于list-watch的Kubernetes异步事件处理框架详解-客户端部分。list本身是一个简单的列表操作,和其它apiserver的增删改操作一样,不再多描述细节。
Informer
简介
Informer 是 Client-go 中的一个核心工具包。在 Kubernetes 源码中,如果 Kubernetes 的某个组件,需要 List/Get Kubernetes 中的 Object,在绝大多 数情况下,会直接使用 Informer 实例中的 Lister()方法(该方法包含 了 Get 和 List 方法),而很少直接请求 Kubernetes API。Informer 最基本 的功能就是 List/Get Kubernetes 中的 Object。
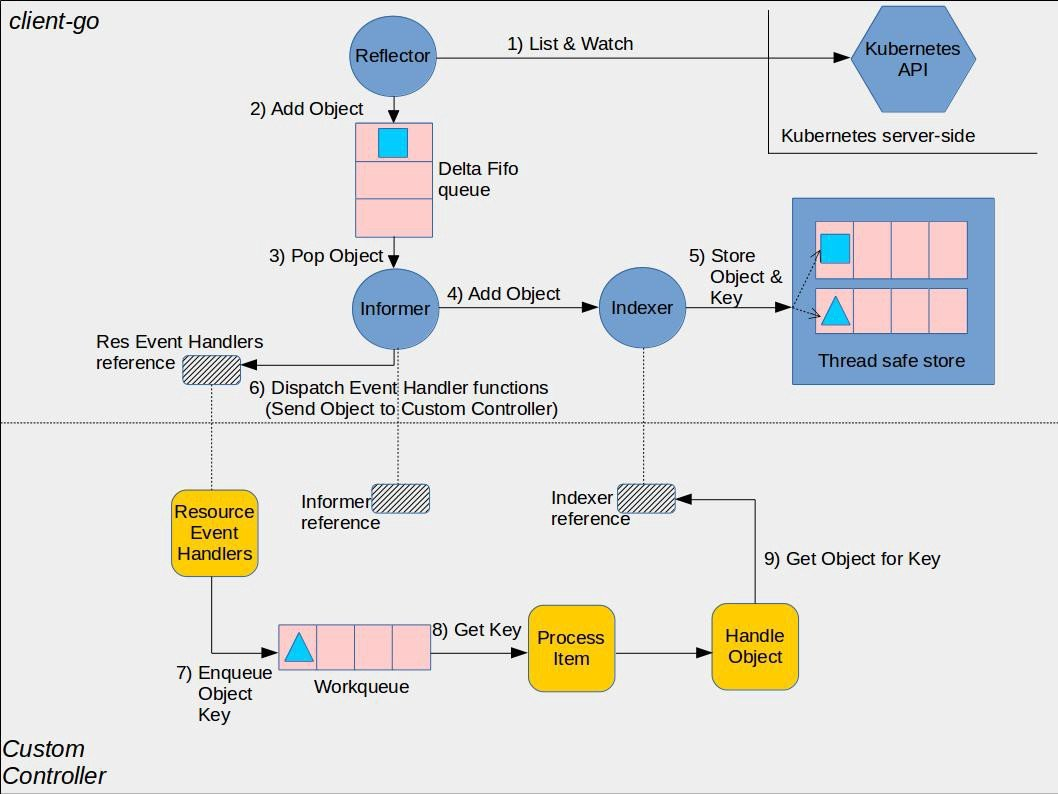
Reflector(反射器
Reflector 用于监控(Watch)指定的 Kubernetes 资源,当监控的资源发生变化时,触发相应的变更事件,例如 Add 事件、Update 事件、Delete 事件,并将其资源对象存放到本地缓存 DeltaFIFO 中。
DeltaFIFO
DeltaFIFO 是一个生产者-消费者的队列,生产者是 Reflector,消费者是 Pop 函数,FIFO 是一个先进先出的队列,而 Delta 是一个资源对象存储,它可以保存资源对象的操作类型,例如 Add 操作类型、Update 操作类型、Delete 操作类型、Sync 操作类型等。
Indexer
Indexer 是 client-go 用来存储资源对象并自带索引功能的本地存储,Reflector 从 DeltaFIFO 中将消费出来的资源对象存储至 Indexer。Indexer 与 Etcd 集群中的数据保持完全一致。这样我们就可以很方便地从本地存储中读取相应的资源对象数据,而无须每次从远程 APIServer 中读取,以减轻服务器的压力。
如下所示,仅需要十行左右的代码就能实现对 Pod 的 List 和 Get。
// 创建一个 informer factory
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30)
// factory已经为所有k8s的内置资源对象提供了创建对应informer实例的方法,调用具体informer实例的Lister或Informer方法
// 就完成了将informer注册到factory的过程
deploymentLister := kubeInformerFactory.Apps().V1().Deployments().Lister()
// 启动注册到factory的所有informer
kubeInformerFactory.Start(stopCh)
Informer 高级功能
Client-go 的首要目标是满足 Kubernetes 的自身需求。Informer 作为其中的核心工具包,面对 Kubernetes 极为复杂业务逻辑,如果仅实现 List/Get 功能,根本无法满足 Kubernetes 自身需求。因此,Informer 被设计为一个灵活而复杂的工具包,除 List/Get Object 外,Informer 还可以监听事件并触发回调函数等,以实现更加复杂的业务逻辑。
Informer 设计思路
Informer 设计中的关键点 为了让 Client-go 更快地返回 List/Get 请求的结果、减少对 Kubenetes API 的直接调用,Informer 被设计实现为一个依赖 Kubernetes List/Watch API 、可监听事件并触发回调函数的二级缓存工具包。
更快地返回 List/Get 请求,减少对 Kubenetes API 的直接调用 使用 Informer 实例的 Lister() 方法, List/Get Kubernetes 中的 Object 时,Informer 不会去请求 Kubernetes API,而是直接查找缓存在本地内存中的数据(这份数据由 Informer 自己维护)。通过这种方式,Informer 既可以更快地返回结果,又能减少对 Kubernetes API 的直接调用。
依赖 Kubernetes List/Watch API Informer 只会调用 Kubernetes List 和 Watch 两种类型的 API。Informer 在初始化的时,先调用 Kubernetes List API 获得某种 resource 的全部 Object,缓存在内存中; 然后,调用 Watch API 去 watch 这种 resource,去维护这份缓存; 最后,Informer 就不再调用 Kubernetes 的任何 API。
用 List/Watch 去维护缓存、保持一致性是非常典型的做法,但令人费解的是,Informer 只在初始化时调用一次 List API,之后完全依赖 Watch API 去维护缓存,没有任何 resync 机制。
可监听事件并触发回调函数 Informer 通过 Kubernetes Watch API 监听某种 resource 下的所有事件。而且,Informer 可以添加自定义的回调函数,这个回调函数实例(即 ResourceEventHandler 实例)只需实现 OnAdd(obj interface{}) OnUpdate(oldObj, newObj interface{}) 和 OnDelete(obj interface{}) 三个方法,这三个方法分别对应 informer 监听到创建、更新和删除这三种事件类型。
在 Controller 的设计实现中,会经常用到 informer 的这个功能。 Controller 相关文章请见此文《如何用 client-go 拓展 Kubernetes 的 API》。
二级缓存 二级缓存属于 Informer 的底层缓存机制,这两级缓存分别是 DeltaFIFO 和 LocalStore。
这两级缓存的用途各不相同。DeltaFIFO 用来存储 Watch API 返回的各种事件 ,LocalStore 只会被 Lister 的 List/Get 方法访问 。
虽然 Informer 和 Kubernetes 之间没有 resync 机制,但 Informer 内部的这两级缓存之间存在 resync 机制。
以上是 Informer 设计中的一些关键点,没有介绍一些太细节的东西,尤其对于 Informer 两级缓存还未做深入介绍。下一章节将对 Informer 详细的工作流程做一个详细介绍。
Informer 详细解析 Informer 内部主要组件 Informer 中主要包含 Controller、Reflector、DeltaFIFO、LocalStore、Lister 和 Processor 六个组件,其中 Controller 并不是 Kubernetes Controller,这两个 Controller 并没有任何联系;Reflector 的主要作用是通过 Kubernetes Watch API 监听某种 resource 下的所有事件;DeltaFIFO 和 LocalStore 是 Informer 的两级缓存;Lister 主要是被调用 List/Get 方法;Processor 中记录了所有的回调函数实例(即 ResourceEventHandler 实例),并负责触发这些函数。
Informer 关键逻辑解析 我们以 Pod 为例,详细说明一下 Informer 的关键逻辑:
Informer 在初始化时,Reflector 会先 List API 获得所有的 Pod Reflect 拿到全部 Pod 后,会将全部 Pod 放到 Store 中 如果有人调用 Lister 的 List/Get 方法获取 Pod, 那么 Lister 会直接从 Store 中拿数据
Informer 在初始化时,Reflector 会先 List API 获得所有的 Pod Reflect 拿到全部 Pod 后,会将全部 Pod 放到 Store 中 如果有人调用 Lister 的 List/Get 方法获取 Pod, 那么 Lister 会直接从 Store 中拿数据
Informer 初始化完成之后,Reflector 开始 Watch Pod,监听 Pod 相关 的所有事件;如果此时 pod_1 被删除,那么 Reflector 会监听到这个事件 Reflector 将 pod_1 被删除 的这个事件发送到 DeltaFIFO DeltaFIFO 首先会将这个事件存储在自己的数据结构中(实际上是一个 queue),然后会直接操作 Store 中的数据,删除 Store 中的 pod_1 DeltaFIFO 再 Pop 这个事件到 Controller 中
Controller 收到这个事件,会触发 Processor 的回调函数
LocalStore 会周期性地把所有的 Pod 信息重新放到 DeltaFIFO 中