Ceph Monitor 详解
Ceph Monitor 架构分析
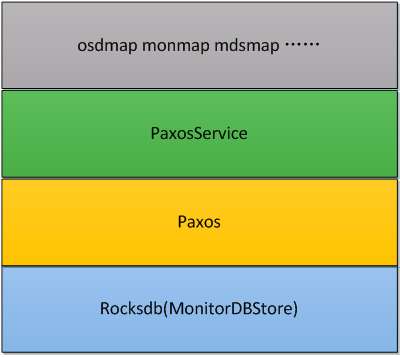
Ceph Monitor 的内部包含kv数据、Paxos模块以及一系列的业务模块。从下往上分别是MonitorDBStore、Paxos、PaxosService、osdmap/monmap/mdsmap…
MonitorDBStore 是对底层DB的抽象封装,将DB的基本操作事务封装成统一接口,当前DB默认使用rocksdb。
PaxosService 负责保证每次都只会有一个提案进入paxos流程。
Paxos 模块具体实现了multi-Paxos算法。
XXXmap 是经过Paxos处理后的资源列表。
从代码角度看,Monitor 启动有五个步骤:
preinit() -> bootstrap() -> _reset() -> ms_dispatch() -> refresh_from_paxos()
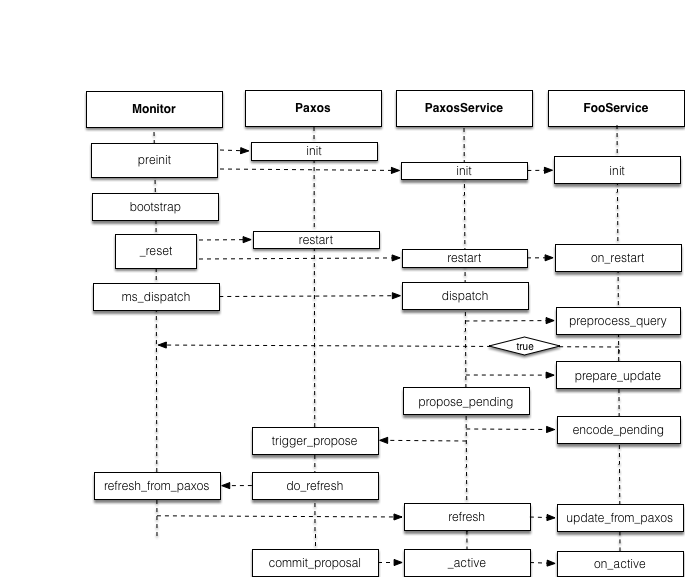
PreInit
monitor进程启动的时候,会初始化paxos及其服务,如果服务需要特殊初始化。调用流程如下:
Monitor::preinit() -> Monitor::init_paxos() -> FooService::init()
Bootstrap
monitor进程在很多情况下会重新进入bootstrap流程,这个过程会重启服务。调用流程如下:
Monitor::bootstrap() -> Monitor::_reset() -> PaxosService::restart() -> FooService::on_restart()
Refresh
决议完成后,需要更新决议的内容。调用流程如下:
Paxos::do_refresh() -> Monitor::refresh_from_paxos() -> PaxosService::refresh() -> FooService::update_from_paxos()
Active
更新完成后,需要执行最开始的回调,然后重新回到 active 状态,服务需要重载 PaxosService::on_active 接口。
Process
Paxos 模块定位是,paxos 算法模型+消息发送,数据只是 bytes;PaxosService 模式的定位是有数据类型的 paxos,并提供根据数据类型的一些方法,比如 monmap。调用流程如下所示:
PaxosService::dispatch() -> PaxosService::propose_pending() -> PaxosService::encode_pending()
依次看一下代码:
bool PaxosService::dispatch(MonOpRequestRef op)
{
// ...
// 确认选举的 epoch 值越来越大
if (m->rx_election_epoch &&
m->rx_election_epoch < mon.get_epoch()) {
dout(10) << " discarding forwarded message from previous election epoch "
<< m->rx_election_epoch << " < " << mon.get_epoch() << dendl;
return true;
}
// 确认客户连接处于激活状态。
if (m->get_connection() &&
!m->get_connection()->is_connected() &&
m->get_connection() != mon.con_self &&
m->get_connection()->get_messenger() != NULL) {
dout(10) << " discarding message from disconnected client "
<< m->get_source_inst() << " " << *m << dendl;
return true;
}
// 确认monmap可读且是最新的。
if (!is_readable(m->version)) {
dout(10) << " waiting for paxos -> readable (v" << m->version << ")" << dendl;
wait_for_readable(op, new C_RetryMessage(this, op), m->version);
return true;
}
// 预处理
if (preprocess_query(op))
return true; // easy!
// 非leader,转发消息
if (!mon.is_leader()) {
mon.forward_request_leader(op);
return true;
}
// 如果目前不可更新,等待重试
if (!is_writeable()) {
dout(10) << " waiting for paxos -> writeable" << dendl;
wait_for_writeable(op, new C_RetryMessage(this, op));
return true;
}
// 准备更新
if (!prepare_update(op)) {
return true;
}
// 处理紧急预案
if (need_immediate_propose) {
dout(10) << __func__ << " forced immediate propose" << dendl;
need_immediate_propose = false;
propose_pending();
return true;
}
// 预案处理
double delay = 0.0;
if (!should_propose(delay)) {
dout(10) << " not proposing" << dendl;
return true;
}
if (delay == 0.0) {
propose_pending();
return true;
}
// ...
}
PaxosService::propose_pending()调用Paxos::propose_new_value(),称作commit。MonmapService之类的都通过propose_ending()实现提交,不需要直接调用propose_new_value()。propose_pending()中调用了encode_pendine()。
void PaxosService::propose_pending()
{
// ...
// 获取paxos的transaction
MonitorDBStore::TransactionRef t = paxos.get_pending_transaction();
if (should_stash_full())
encode_full(t);
// 将决议编码入 transaction 中
encode_pending(t);
have_pending = false;
if (format_version > 0) {
t->put(get_service_name(), "format_version", format_version);
}
// 发起决议
proposing = true;
class C_Committed : public Context {
PaxosService *ps;
public:
explicit C_Committed(PaxosService *p) : ps(p) { }
void finish(int r) override {
ps->proposing = false;
if (r >= 0)
ps->_active();
else if (r == -ECANCELED || r == -EAGAIN)
return;
else
ceph_abort_msg("bad return value for C_Committed");
}
};
paxos.queue_pending_finisher(new C_Committed(this));
paxos.trigger_propose();
}
PaxosService::encode_pending()抽象函数,由子类覆盖。通过它能找到子类负责什么样的数据。
void MDSMonitor::encode_pending(MonitorDBStore::TransactionRef t)
{
auto &pending = get_pending_fsmap_writeable();
auto &epoch = pending.epoch;
dout(10) << "encode_pending e" << epoch << dendl;
print_map<30>(pending);
if (!g_conf()->mon_mds_skip_sanity) {
pending.sanity(true);
}
// 记录修改时间到 mds_map 中
for (auto &p : pending.filesystems) {
if (p.second->mds_map.epoch == epoch) {
p.second->mds_map.modified = ceph_clock_now();
}
}
// apply to paxos
ceph_assert(get_last_committed() + 1 == pending.epoch);
bufferlist pending_bl;
pending.encode(pending_bl, mon.get_quorum_con_features());
// 将所有的数据放进 tranction
put_version(t, pending.epoch, pending_bl);
put_last_committed(t, pending.epoch);
// MDSHealth 数据编码
for (std::map<uint64_t, MDSHealth>::iterator i = pending_daemon_health.begin();
i != pending_daemon_health.end(); ++i) {
bufferlist bl;
i->second.encode(bl);
t->put(MDS_HEALTH_PREFIX, stringify(i->first), bl);
}
for (std::set<uint64_t>::iterator i = pending_daemon_health_rm.begin();
i != pending_daemon_health_rm.end(); ++i) {
t->erase(MDS_HEALTH_PREFIX, stringify(*i));
}
pending_daemon_health_rm.clear();
remove_from_metadata(pending, t);
// 健康检查
health_check_map_t new_checks;
const auto &info_map = pending.get_mds_info();
for (const auto &i : info_map) {
const auto &gid = i.first;
const auto &info = i.second;
if (pending_daemon_health_rm.count(gid)) {
continue;
}
MDSHealth health;
auto p = pending_daemon_health.find(gid);
if (p != pending_daemon_health.end()) {
health = p->second;
} else {
bufferlist bl;
mon.store->get(MDS_HEALTH_PREFIX, stringify(gid), bl);
if (!bl.length()) {
derr << "Missing health data for MDS " << gid << dendl;
continue;
}
auto bl_i = bl.cbegin();
health.decode(bl_i);
}
for (const auto &metric : health.metrics) {
if (metric.type == MDS_HEALTH_DUMMY) {
continue;
}
const auto rank = info.rank;
health_check_t *check = &new_checks.get_or_add(
mds_metric_name(metric.type),
metric.sev,
mds_metric_summary(metric.type),
1);
ostringstream ss;
ss << "mds." << info.name << "(mds." << rank << "): " << metric.message;
bool first = true;
for (auto &p : metric.metadata) {
if (first) {
ss << " ";
} else {
ss << ", ";
}
ss << p.first << ": " << p.second;
first = false;
}
check->detail.push_back(ss.str());
}
}
pending.get_health_checks(&new_checks);
for (auto& p : new_checks.checks) {
p.second.summary = std::regex_replace(
p.second.summary,
std::regex("%num%"),
stringify(p.second.detail.size()));
p.second.summary = std::regex_replace(
p.second.summary,
std::regex("%plurals%"),
p.second.detail.size() > 1 ? "s" : "");
p.second.summary = std::regex_replace(
p.second.summary,
std::regex("%isorare%"),
p.second.detail.size() > 1 ? "are" : "is");
p.second.summary = std::regex_replace(
p.second.summary,
std::regex("%hasorhave%"),
p.second.detail.size() > 1 ? "have" : "has");
}
encode_health(new_checks, t);
}
void Paxos::propose_pending()
{
ceph_assert(is_active());
ceph_assert(pending_proposal);
cancel_events();
bufferlist bl;
pending_proposal->encode(bl);
dout(10) << __func__ << " " << (last_committed + 1)
<< " " << bl.length() << " bytes" << dendl;
dout(30) << __func__ << " transaction dump:\n";
JSONFormatter f(true);
pending_proposal->dump(&f);
f.flush(*_dout);
*_dout << dendl;
pending_proposal.reset();
committing_finishers.swap(pending_finishers);
state = STATE_UPDATING;
begin(bl);
}
Monitor模块
2. Monitor walkthrough
[Mon0]
init()
bootstrap()
if get_epoch == 0:
calc_legacy_ranks()
checkrank && updaterank
state = STATE_PROBING
send_message(new MMonProbe(OP_PROBE..)..)
[Mon1]
dispatch()
handle_probe_probe()
if !is_probing() && !is_synchronizing():
bootstrap()
send_message(new MMonProbe(OP_REPLY..)..)
[Mon2]
dispatch()
handle_proble_reply()
if newer monmap:
use new monmap
bootstrap()
if epoch == 0 && peer_name.contain("noname-"):
bootstrap()
if paxos->get_version() < m->paxos_first_version && m->paxos_first_version > 1 // my paxos verison is too low
sync_start()
if paxos->get_version() + g_conf->paxos_max_join_drift < m->paxos_last_version
sync_start()
if I'm part of cluster
start_election()
if outside_quorum.size() >= monmap->size() / 2 + 1 // major quorum are out of cluster
start_election()
----------------------------------------------------------
[election process] 编号小的mon胜利(entity_name_t._num,也是mon->rank)
1. 每个Elector都向其它人发proposal,申请自己是leader
2. 每个Elector收到其他人的proposal请求后记入leader_acked, m->get_source().num(), 自己mon->rank,谁小就defer到谁。
defer()会发送OP_ACK消息
3. 收到ACK的Elector,会检查如果acked_me.size() == mon->monmap->size(),则victory()
start_election()
elector.call_election()
if (epoch % 2 == 0) // 奇数为选举状态,偶数为稳定状态
bump_epoch(epoch+1)
electing_me = true;
broadcast to all
send_message(new MMonElection(OP_PROPOSE, epoch, mon->monmap))
Monitor.dispatch()
case MSG_MON_ELECTION:
elector.dispatch(m)
if (peermap->epoch > mon->monmap->epoch)
mon->monmap->decode(em->monmap_bl)
mon->bootstrap()
switch (em->op)
case MMonElection::OP_PROPOSE:
handle_propose(em)
if ignoring propose without required features
nak_old_peer()
return
if (m->epoch > epoch)
bump_epoch()
mon->join_election()
if (m->epoch < epoch) // got an "old" propose
...
return
if (mon->rank < from) // i would win over them.
...
else
defer(from)
send_message(new MMonElection(OP_ACK, epoch, mon->monmap), from)
Elector.dispatch()
case MMonElection::OP_ACK:
handle_ack(em)
if (m->epoch > epoch)
bump_epoch(m->epoch);
start()
return
if (electing_me) // thanks
if (acked_me.size() == mon->monmap->size())
victory()
change cmd set
for each one
send_message(new MMonElection(OP_VICTORY, epoch, mon->monmap), mon->monmap->get_inst(*p))
mon->win_election()
state = STATE_LEADER
paxos->leader_init()
monmon()->election_finished()
Elector.dispatch()
case MMonElection::OP_VICTORY:
handle_victory()
mon->lose_election()
stash leader's commands
---------------------
1. Mon sync_start()
/*同步的内容是paxos->get_version(), 整个
*/
[mon0]
sync_start()
state = STATE_SYNCHRONIZING
sync_provider = other
send_message(new MMonSync(sync_full?OP_GET_COOKIE_FULL:OP_GET_COOKIE_RECENT), sync_provider)
[mon1]
dispatch()
handle_sync_get_cookie()
MMonSync *reply = new MMonSync(MMonSync::OP_COOKIE, sp.cookie);
reply->last_committed = sp.last_committed;
messenger->send_message(reply, m->get_connection());
[mon0]
dispatch()
handle_sync()
handle_sync_cookie()
sync_cookie = m->cookie;
sync_start_version = m->last_committed;
MMonSync *r = new MMonSync(MMonSync::OP_GET_CHUNK, sync_cookie);
messenger->send_message(r, sync_provider);
[mon1]
dispatch()
handle_sync()
handle_sync_get_chunk()
MMonSync *reply = new MMonSync(MMonSync::OP_CHUNK, sp.cookie);
MonitorDBStore::Transaction tx;
tx.put(paxos->get_name(), sp.last_committed, bl);
sp.synchronizer->get_chunk_tx(tx, left); // 拷贝整个MonitorDBStore
::encode(tx, reply->chunk_bl);
if no next chunk
reply->op = MMonSync::OP_LAST_CHUNK;
messenger->send_message(reply, m->get_connection());
[mon0]
dispatch()
handle_sync()
handle_sync_chunk()
MonitorDBStore::Transaction tx;
tx.append_from_encoded(m->chunk_bl);
store->apply_transaction(tx);
if OP_LAST_CHUNK
sync_finish(m->last_committed);
init_paxos();
bootstrap();
---------------------------------------------------------
1. Paxos & PaxosService
2. Monitor::preinit()中,调用了
paxos->init();
for (int i = 0; i < PAXOS_NUM; ++i) {
paxos_service[i]->init();
}
Monitor::_reset中,调用了
paxos->restart();
for (vector<PaxosService*>::iterator p = paxos_service.begin(); p != paxos_service.end(); ++p)
(*p)->restart();
Monitor::win_election()中,调用了
paxos->leader_init()
monmon()->election_finished();
for (vector<PaxosService*>::iterator p = paxos_service.begin(); p != paxos_service.end(); ++p) {
if (*p != monmon())
(*p)->election_finished();
}
Monitor::lose_election()中,调用了
paxos->peon_init()
for (vector<PaxosService*>::iterator p = paxos_service.begin(); p != paxos_service.end(); ++p)
(*p)->election_finished();
1.5. Paxos leader collect
leader_init()
...
collect(0);
[mon0]
collect(0) //leader
state = STATE_RECOVERING;
// look for uncommitted value
if (get_store()->exists(get_name(), last_committed+1)) {
version_t v = get_store()->get(get_name(), "pending_v");
version_t pn = get_store()->get(get_name(), "pending_pn");
uncommitted_pn = pn;
uncommitted_v = last_committed+1;
get_store()->get(get_name(), last_committed+1, uncommitted_value);
}
// pick new pn
accepted_pn = get_new_proposal_number(MAX(accepted_pn, oldpn));
// send collect
for (set<int>::const_iterator p = mon->get_quorum().begin(); p != mon->get_quorum().end(); ++p) {
if (*p == mon->rank) continue;
MMonPaxos *collect = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_COLLECT, ceph_clock_now(g_ceph_context));
collect->last_committed = last_committed;
collect->first_committed = first_committed;
collect->pn = accepted_pn;
mon->messenger->send_message(collect, mon->monmap->get_inst(*p));
}
[mon1]
handle_collect() //peon
state = STATE_RECOVERING
MMonPaxos *last = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_LAST, ceph_clock_now(g_ceph_context));
last->last_committed = last_committed;
last->first_committed = first_committed;
// can we accept this pn?
if (collect->pn > accepted_pn) {
accepted_pn = collect->pn;
MonitorDBStore::Transaction t;
t.put(get_name(), "accepted_pn", accepted_pn);
}
// share whatever committed values we have
if (collect->last_committed < last_committed)
share_state(last, collect->first_committed, collect->last_committed) // 把我的过去多个commit放到了last中
for ( ; v <= last_committed; v++) {
if (get_store()->exists(get_name(), v)) {
get_store()->get(get_name(), v, m->values[v]);
}
}
m->last_committed = last_committed;
// do we have an accepted but uncommitted value?
// (it'll be at last_committed+1)
if (collect->last_committed <= last_committed && get_store()->exists(get_name(), last_committed+1)) {
get_store()->get(get_name(), last_committed+1, bl);
last->values[last_committed+1] = bl;
version_t v = get_store()->get(get_name(), "pending_v");
version_t pn = get_store()->get(get_name(), "pending_pn");
last->uncommitted_pn = pn;
}
// send reply
mon->messenger->send_message(last, collect->get_source_inst());
[mon0]
handle_last() // leader
// store any committed values if any are specified in the message
need_refresh = store_state(last);
// do they accept your pn?
if (last->pn > accepted_pn) {
// no, try again
collect(last->pn);
} else if (last->pn == accepted_pn) {
// yes, they do. great!
num_last++;
// did this person send back an accepted but uncommitted value?
if (last->uncommitted_pn) {
if (last->uncommitted_pn >= uncommitted_pn && last->last_committed >= last_committed && last->last_committed + 1 >= uncommitted_v) {
// we learned an uncommitted value
uncommitted_v = last->last_committed+1;
uncommitted_pn = last->uncommitted_pn;
uncommitted_value = last->values[uncommitted_v];
}
}
// is that everyone?
if (num_last == mon->get_quorum().size()) {
// share committed values?
for (map<int,version_t>::iterator p = peer_last_committed.begin(); p != peer_last_committed.end(); ++p) {
if (p->second < last_committed) {
// share committed values
MMonPaxos *commit = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_COMMIT, ceph_clock_now(g_ceph_context));
share_state(commit, peer_first_committed[p->first], p->second);
mon->messenger->send_message(commit, mon->monmap->get_inst(p->first));
}
}
// did we learn an old value?
if (uncommitted_v == last_committed+1 && uncommitted_value.length()) {
state = STATE_UPDATING_PREVIOUS;
begin(uncommitted_value);
} else{
finish_round();
state = STATE_ACTIVE
}
} else {
// this is an old message, discard
}
2. Paxos proposal
PaxosService::dispatch(m)
preprocess_query(PaxosServiceMessage* m)
if (!mon->is_leader()) {
mon->forward_request_leader(m);
return true;
}
prepare_update(m)
if (should_propose(delay)) {
if (delay == 0.0) {
propose_pending();
}
[mon0]
PaxosService::propose_pending()
Paxos::propose_new_value()
queue_proposal(bl, onfinished);
proposed_queued()
C_Proposal *proposal = static_cast<C_Proposal*>(proposals.front());
proposal->proposed = true;
state = STATE_UPDATING;
begin(proposal->bl); //leader
// accept it ourselves
accepted.clear();
accepted.insert(mon->rank);
new_value = v;
// store the proposed value in the store.
MonitorDBStore::Transaction t;
t.put(get_name(), last_committed+1, new_value);
t.put(get_name(), "pending_v", last_committed + 1);
t.put(get_name(), "pending_pn", accepted_pn);
get_store()->apply_transaction(t);
// ask others to accept it too!
for (set<int>::const_iterator p = mon->get_quorum().begin(); p != mon->get_quorum().end(); ++p) {
if (*p == mon->rank) continue;
MMonPaxos *begin = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_BEGIN, ceph_clock_now(g_ceph_context));
begin->values[last_committed+1] = new_value;
begin->last_committed = last_committed;
begin->pn = accepted_pn;
mon->messenger->send_message(begin, mon->monmap->get_inst(*p));
}
// set timeout event
accept_timeout_event = new C_AcceptTimeout(this);
mon->timer.add_event_after(g_conf->mon_accept_timeout, accept_timeout_event); // 如果accept长时间未完成,则触发accept_timeout
[mon1..n]
handle_begin() //peon
if (begin->pn < accepted_pn) {return;}
state = STATE_UPDATING;
version_t v = last_committed+1;
MonitorDBStore::Transaction t;
t.put(get_name(), v, begin->values[v]);
t.put(get_name(), "pending_v", v);
t.put(get_name(), "pending_pn", accepted_pn);
get_store()->apply_transaction(t);
MMonPaxos *accept = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_ACCEPT,
ceph_clock_now(g_ceph_context));
accept->pn = accepted_pn;
accept->last_committed = last_committed;
mon->messenger->send_message(accept, begin->get_source_inst());
[mon0]
handle_accept() //leader
accepted.insert(from);
// new majority?
if (accepted.size() == (unsigned)mon->monmap->size()/2+1) {
commit();
MonitorDBStore::Transaction t;
// commit locally
last_committed++;
last_commit_time = ceph_clock_now(g_ceph_context);
t.put(get_name(), "last_committed", last_committed);
for (set<int>::const_iterator p = mon->get_quorum().begin(); p != mon->get_quorum().end(); ++p) {
if (*p == mon->rank) continue;
MMonPaxos *commit = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_COMMIT, ceph_clock_now(g_ceph_context));
commit->values[last_committed] = new_value;
commit->pn = accepted_pn;
commit->last_committed = last_committed;
mon->messenger->send_message(commit, mon->monmap->get_inst(*p));
}
do_refresh() // to notify PaxosService subclasses
...
commit_proposal()
C_Proposal *proposal = static_cast<C_Proposal*>(proposals.front());
proposals.pop_front();
proposal->complete(0);
// done?
if (accepted == mon->get_quorum()) {
extend_lease();
lease_expire = ceph_clock_now(g_ceph_context);
lease_expire += g_conf->mon_lease;
acked_lease.clear();
acked_lease.insert(mon->rank);
for (set<int>::const_iterator p = mon->get_quorum().begin(); p != mon->get_quorum().end(); ++p) {
if (*p == mon->rank) continue;
MMonPaxos *lease = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_LEASE, ceph_clock_now(g_ceph_context));
lease->last_committed = last_committed;
lease->lease_timestamp = lease_expire;
lease->first_committed = first_committed;
mon->messenger->send_message(lease, mon->monmap->get_inst(*p));
}
finish_round();
state = STATE_ACTIVE;
}
[mon1..n]
handle_commit(MMonPaxos *commit)
store_state(commit)
start, end = ... // we want to write the range [last_committed, m->last_committed] only.
for (it = start; it != end; ++it) {
t.put(get_name(), it->first, it->second);
decode_append_transaction(t, it->second);
}
get_store()->apply_transaction(t);
do_refresh()
/*
I guess
last_committed表示paxos算法instance
version_t表示一个算法instance内,proposal的编号
如果accept长时间未完成,则触发accept_timeout
如果peon长时间为达成一致accept,那么extend_lease()就不会为它们执行,它们会发生lease_timeout
Monitor所用的paxos似乎是一种改进版的paxos。
首先保证有且仅有一个leader。
然后phase1只需要在leader初始时运行一次。
之后的propose只需要phase2。
*/
------------------ OP_LEASE process ----------------
[mon0]
extend_lease(); // extend lease of other mon
[mon1..n]
handle_lease()
lease_expire = lease->lease_timestamp;
state = STATE_ACTIVE;
// ack
MMonPaxos *ack = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_LEASE_ACK, ceph_clock_now(g_ceph_context));
ack->last_committed = last_committed;
ack->first_committed = first_committed;
ack->lease_timestamp = ceph_clock_now(g_ceph_context);
mon->messenger->send_message(ack, lease->get_source_inst());
// (re)set timeout event.
reset_lease_timeout();
[mon0]
handle_lease_ack()
if (acked_lease == mon->get_quorum()) {
mon->timer.cancel_event(lease_ack_timeout_event);
lease_ack_timeout_event = 0;
}
---------------- OP_ACCEPT timeout ----------------
void Paxos::accept_timeout()
mon->bootstrap();
-----------------How paxos value is read -----------------
Paxos::handle_last() or handle_accept() or handle_commit() in the end
Paxos::do_refresh()
mon->refresh_from_paxos(&need_bootstrap);
for (int i = 0; i < PAXOS_NUM; ++i) {
paxos_service[i]->refresh(need_bootstrap);
// update cached versions
cached_first_committed = mon->store->get(get_service_name(), first_committed_name);
cached_last_committed = mon->store->get(get_service_name(), last_committed_name);
update_from_paxos(need_bootstrap) // implemented by subclasses, below use code of MonmapMonitor
version_t version = get_last_committed();
int ret = get_version(version, monmap_bl);
mon->monmap->decode(monmap_bl);
}
for (int i = 0; i < PAXOS_NUM; ++i) {
paxos_service[i]->post_paxos_update() // implemented by subclasses, below use code of MonmapMonitor
// 什么都没写
}
/*
假如不是MonmapMonitor的commit,MonmapMonitor也给refresh了怎么办?
update_from_paxos()中get_version()对应的put_version()在encode_pending()中。
get_version()并不是直接从paxos中拿,而是从get(get_service_name(), ver, bl)的get_service_name()中拿
*/
----------------- MonClient how to get ----------------
MonClient::get_monmap()
_sub_want("monmap", 0, 0);
while (want_monmap)
map_cond.Wait(monc_lock);
[MonClient]
MonClient::_reopen_session()
if (!sub_have.empty())
_renew_subs();
MMonSubscribe *m = new MMonSubscribe;
m->what = sub_have;
_send_mon_message(m);
[Monitor]
dispatch()
handle_subscribe()
for (map<string,ceph_mon_subscribe_item>::iterator p = m->what.begin(); p != m->what.end(); ++p){
session_map.add_update_sub(s, p->first, p->second.start, p->second.flags & CEPH_SUBSCRIBE_ONETIME, m->get_connection()->has_feature(CEPH_FEATURE_INCSUBOSDMAP));
}
[OSDMonitor]
OSDMonitor::update_from_paxos()
check_subs()
check_sub()
send_incremental(sub->next, sub->session->inst, sub->incremental_onetime);
[MDSMonitor]
同OSDMonitor
-------------------------
[MonClient]
MonClient::get_monmap_privately()
messenger->send_message(new MMonGetMap, cur_con)
[Monitor]
dispatch()
case CEPH_MSG_MON_GET_MAP:
handle_mon_get_map(static_cast<MMonGetMap*>(m));
send_latest_monmap(m->get_connection().get());
messenger->send_message(new MMonMap(bl), con);
[MonClient]
ms_dispatch()
case CEPH_MSG_MON_MAP:
handle_monmap(static_cast<MMonMap*>(m));
::decode(monmap, p);
map_cond.Signal();
Message 模块解析
更多技术分享浏览我的博客:
https://thierryzhou.github.io