Ceph快照详解
简介
Ceph快照功能基于RADOS实现,但是从使用方法上分成三种情况:
- Pool Snapshot 对整个Pool打快照,该Pool中所有的对象都会受影响。
- Self Managed Snapshot 用户管理的快照,Pool受影响的对象是受用户控制的,这里的用户往往是应用,如librbd。常见的形式就是针对某一个rbd卷进行快照。
- 用于CephFS的快照,在Ceph 16.x以后的版本中,CephFS默认情况下已经开启了快照功能的,但是由于CephFS的快照也是基于Pool Snapshot开发的因此在多文件系统的情况时,MDS的集群之间snapID相互独立,这个快照管理带来了极大的不便,此种情况下官方不推荐开启快照功能。
快照的原理
Ceph的快照与其他系统的快照一样,是基于COW(copy-on-write)实现的。其实现由RADOS支持,基于OSD服务端——每次做完快照后再对卷进行写入时就会触发COW操作,即先拷贝出原数据对象的数据出来生成快照对象,然后对原数据对象进行写入。于此同时,每次快照的操作会更新卷的元数据,以及包括快照ID,快照链,parent信息等在内的快照信息。
此外image快照和pool快照的区别是由不同的使用方式导致的,底层的实现没有本质上的区别。从OSD的角度看,池快照和自管理的快照之间的区别在于SnapContext是通过客户端的MOSDOp还是通过最新的OSDMap到达osd。
快照的使用
image快照与pool快照 image快照与pool快照是互斥的,创建了image的存储池无法创建存储池的快照,因为存储池当前已经为unmanaged snaps mode了,而没有创建image的就可以做存储池快照。而如果创建了pool快照则无法创建image快照。
// image快照的创建命令:
rbd snap create {pool-name}/{image-name}@{snap-name}
// 回滚命令:
rbd snap rollback {pool-name}/{image-name}@{snap-name}
CephFS快照 CephFS的无法通过命令行直接操作,需要通过操作文件夹的方式来操作快照
// 为某个文件夹创建快照
mkdir .snap/snapname // snapname为快照的名称
//恢复数据的命令
p -ra .snap/snap1/* ./
//删除快照的命令
rmdir .snap/snap1
快照的实现
快照的相关概念
pool :每个池都是逻辑上的隔离单位,不同的 pool 可以有不同的数据处理方式,包括: ReplicasSet,Placement Groups,CRUSH。 (Rules/Snapshot/ownership 都是通过池隔离。)
head 对象:卷原始对象,包含了 SnapSet(详见关键数据结构部分)。
snap 对象:卷打快照后通过 cow 拷贝出来的对象,该对象为只读。
snap_seq: 快照的序列号(详见关键数据结构部分)。
snapdir 对象: head 对象被删除后,仍然有 snap 和 clone 对象,系统自动创建一个 snapdir 对象来保存 snapset 的信息。(详见关键数据结构部分)。
rbd_header 对象: 在 rados 中,对象里没有数据,卷的元数据都是作为这个对象的属性以 omap 方式记录到 leveldb 里。
快照的代码实现
使用 librados api 创建快照,其代码如下:
#include <iostream>
#include <string>
#include <rados/librados.hpp>
int main(int argc, const char **argv)
{
int ret = 0;
librados::Rados rados;
librados::IoCtx io_ctx
char cluster_name[] = "ceph";
char user_name[] = "client.admin";
uint64_t flags = 0;
/* 初始化一个ceph集群对象 */
{
ret = rados.init2(user_name, cluster_name, flags);
if (ret < 0) {
std::cerr << "Couldn't initialize the cluster handle! error " << ret << std::endl;
return EXIT_FAILURE;
} else {
std::cout << "Created a cluster handle." << std::endl;
}
ret = rados.conf_read_file("/etc/ceph/ceph.conf");
if (ret < 0) {
std::cerr << "Couldn't read the Ceph configuration file! error " << ret << std::endl;
return EXIT_FAILURE;
} else {
std::cout << "Read the Ceph configuration file." << std::endl;
}
ret = rados.conf_parse_argv(argc, argv);
if (ret < 0) {
std::cerr << "Couldn't parse command line options! error " << ret << std::endl;
return EXIT_FAILURE;
} else {
std::cout << "Parsed command line options." << std::endl;
}
ret = rados.connect();
if (ret < 0) {
std::cerr << "Couldn't connect to cluster! error " << ret << std::endl;
return EXIT_FAILURE;
} else {
std::cout << "Connected to the cluster." << std::endl;
}
}
/* 创建存储池,并创建快照 */
{
rados.ioctx_create("my_test_pool", io_ctx);
io_ctx.stat(&stats);
// 创建快照
int oid = io_ctx.snap_create("my_test_snapshot");
// 使用快照,恢复快照
io_ctx.snap_rollback(oid, "my_test_snapshot");
}
return 0;
}
IoCtx 对象是 C++ API 接口中关于 IO Content 的抽象层,对应的底层实现在 IoCtxImpl 中,声明如下:
接下来看是 snap_create 和 snap_rollback 的代码:
// src/include/rados/librados.hpp
claszs CEPH_RADOS_API IoCtx
{
// ...
private:
// 通过友元只允许 Rados 对象可以创建 IoCtx 对象
IoCtx(IoCtxImpl *io_ctx_impl_);
friend class Rados;
friend class libradosstriper::RadosStriper;
friend class ObjectWriteOperation;
friend class ObjectReadOperation;
IoCtxImpl *io_ctx_impl;
};
// 代码来源:src/librados/IoCtxImpl.h
struct librados::IoCtxImpl {
std::atomic<uint64_t> ref_cnt = { 0 };
RadosClient *client = nullptr;
int64_t poolid = 0;
snapid_t snap_seq; //根据是否有快照值为snap的快照序号或者CEPH_NOSNAP
::SnapContext snapc; // 快照上下文
// ...
};
在IoCtxImpl里的snap_seq也被称为快照的id,当打开一个image时,如果打开的是一个卷的快照,则该值为快照对应的序号,否则该值为CEPH_NOSNAP表示操作的不是卷的快照,是卷自身。
// src/librados/IoCtx.cc
// 创建快照
int librados::IoCtx::snap_create(const char *snapname)
{
return io_ctx_impl->snap_create(snapname);
}
// 快照回滚
int librados::IoCtx::snap_rollback(const std::string& oid, const char *snapname)
{
return io_ctx_impl->rollback(oid, snapname);
}
/////////////////////////////////////////////////////////
// src/librados/librados_cxx.cc
// 创建快照
int librados::IoCtxImpl::snap_create(const char *snapName)
{
int reply;
string sName(snapName);
ceph::mutex mylock = ceph::make_mutex("IoCtxImpl::snap_create::mylock");
ceph::condition_variable cond;
bool done;
Context *onfinish = new C_SafeCond(mylock, cond, &done, &reply);
objecter->create_pool_snap(poolid, sName, onfinish);
std::unique_lock l{mylock};
cond.wait(l, [&done] { return done; });
return reply;
}
// 快照回滚
int librados::IoCtxImpl::selfmanaged_snap_rollback_object(const object_t& oid,
::SnapContext& snapc,
uint64_t snapid)
{
int reply;
ceph::mutex mylock = ceph::make_mutex("IoCtxImpl::snap_rollback::mylock");
ceph::condition_variable cond;
bool done;
Context *onack = new C_SafeCond(mylock, cond, &done, &reply);
::ObjectOperation op;
prepare_assert_ops(&op);
op.rollback(snapid);
objecter->mutate(oid, oloc,
op, snapc, ceph::real_clock::now(),
extra_op_flags,
onack, NULL);
std::unique_lock l{mylock};
cond.wait(l, [&done] { return done; });
return reply;
}
int librados::IoCtxImpl::rollback(const object_t& oid, const char *snapName)
{
snapid_t snap;
int r = objecter->pool_snap_by_name(poolid, snapName, &snap);
if (r < 0) {
return r;
}
return selfmanaged_snap_rollback_object(oid, snapc, snap);
}
快照的创建
接下来经过 objecter 的处理以后,snapshot 请求被发送给 mon 服务端,经过一些的消息转发,snapshot的请求会被转发到 OSDMonitor 中处理。
在OSD端,对象的Snap相关的信息保存在SnapSet数据结构中,每次IO操作都会带上snap_seq发送给OSD,OSD会查询该IO操作涉及的object的snap_seq情况。当创建一个快照以后,对镜像中的对象进行写操作时会带上新的snap_seq,Ceph接到请求后会先检查对象的Head Version,如果发现该写操作所带有的snap_seq大于原本对象的snap_seq,那么就会对原来的对象克隆一个新的Object Head Version,原来的对象会作为Snapshot,新的Object Head会带上新的snap_seq,也就是librbd之前申请到的。
ceph也有一套Watcher回调通知机制,当别的的客户端做了快照,产生了以新的快照序号,当该客户端访问,osd端知道最新快照需要变化后,通知相应的连接客户端更新最新的快照序号。如果没有及时更新,也没有太大的问题,客户端会主动更新快照序号,然后重新发起写操作。
具体到代码流程如下:
- 判断服务端的快照序号,如果大于客户端的序号,则用服务端的快照信息更新客户端的信息,需要注意的是客户端的序号是不允许小于服务端的序号的,如发生服务端的序号大于客户端的序号则参见上述的watcher回调通知机制。
- 把已经删除的快照过滤掉。
- 如果head对象存在切snaps的size不为空,并且客户端的最新快照序号大于服务端的最新快照序号,则需要克隆对象。
- 克隆完成后修改clone_overlap和clone_size的记录。
- 更新服务端快照信息。 ```cpp // 源码实现:src/mon/OSDMonitor.cc bool OSDMonitor::prepare_pool_op(MonOpRequestRef op) { // pg_pool_t *pp; // … switch (m->op) { case POOL_OP_CREATE_SNAP: if (!pp.snap_exists(m->name.c_str())) { pp.add_snap(m->name.c_str(), ceph_clock_now()); dout(10) « “create snap in pool “ « m->pool « ” “ « m->name « ” seq “ « pp.get_snap_epoch() « dendl; changed = true; } break;
case POOL_OP_DELETE_SNAP: { snapid_t s = pp.snap_exists(m->name.c_str()); if (s) { pp.remove_snap(s); pending_inc.new_removed_snaps[m->pool].insert(s); changed = true; } } break;
case POOL_OP_CREATE_UNMANAGED_SNAP: { uint64_t snapid = pp.add_unmanaged_snap( osdmap.require_osd_release < ceph_release_t::octopus); encode(snapid, reply_data); changed = true; } break;
case POOL_OP_DELETE_UNMANAGED_SNAP: if (!_is_removed_snap(m->pool, m->snapid) && !_is_pending_removed_snap(m->pool, m->snapid)) { if (m->snapid > pp.get_snap_seq()) { _pool_op_reply(op, -ENOENT, osdmap.get_epoch()); return false; } pp.remove_unmanaged_snap( m->snapid, osdmap.require_osd_release < ceph_release_t::octopus); pending_inc.new_removed_snaps[m->pool].insert(m->snapid); // also record the new seq as purged: this avoids a discontinuity // after all of the snaps have been purged, since the seq assigned // during removal lives in the same namespace as the actual snaps. pending_pseudo_purged_snaps[m->pool].insert(pp.get_snap_seq()); changed = true; } break;
case POOL_OP_AUID_CHANGE: _pool_op_reply(op, -EOPNOTSUPP, osdmap.get_epoch()); return false;
default: ceph_abort(); break; }
if (changed) { pp.set_snap_epoch(pending_inc.epoch); pending_inc.new_pools[m->pool] = pp; }
out: wait_for_finished_proposal(op, new OSDMonitor::C_PoolOp(this, op, ret, pending_inc.epoch, &reply_data)); return true; }
// 只列举 pg_pool_t 对象中 add_snap 的操作如何实现: void pg_pool_t::add_snap(const char *n, utime_t stamp) { ceph_assert(!is_unmanaged_snaps_mode()); flags |= FLAG_POOL_SNAPS; snapid_t s = get_snap_seq() + 1; snap_seq = s; snaps[s].snapid = s; snaps[s].name = n; snaps[s].stamp = stamp; }
前文提到过快照通过 COW 方式实现,在没有发生变化是通过集群我们只能观测到 snapid 的变化,快照和原数据是同一份数据,只有当发生了数据写时,Ceph 才会为快照生成相应的数据。写请求从客户端到 Ceph 服务的流程如下所示:
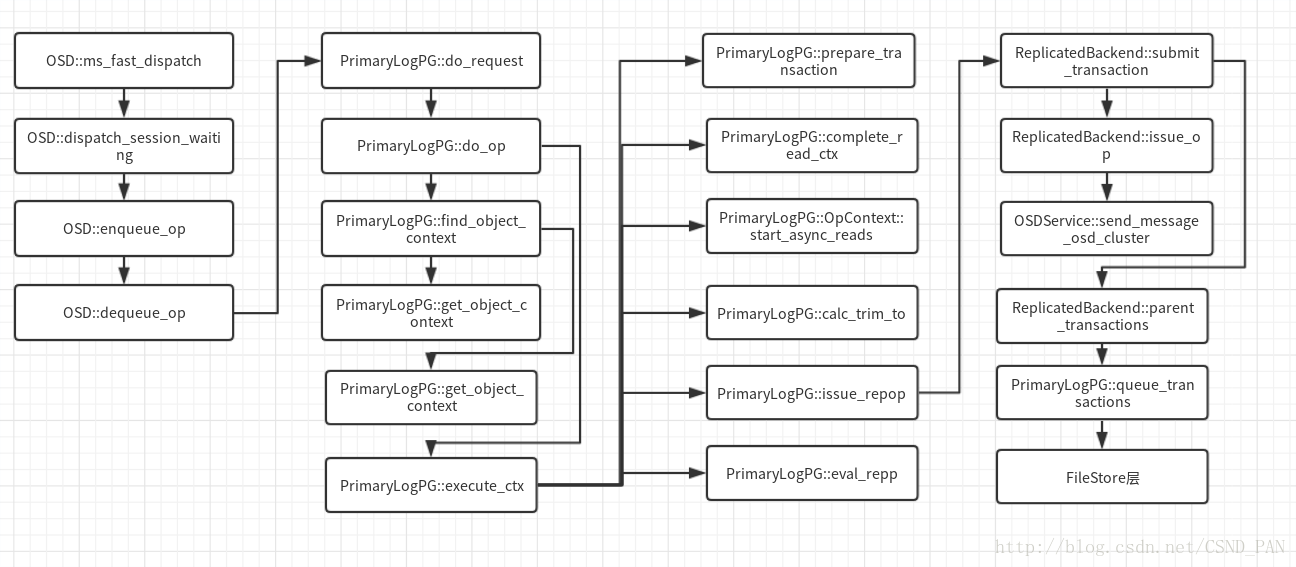
先看一下关键数据结构的定义:
```cpp
// // 源码实现:src/osd/PrimaryLogPG.h
class PrimaryLogPG : public PG, public PGBackend::Listener {
friend class OSD;
friend class Watch;
friend class PrimaryLogScrub;
// ...
struct OpContext {
// ...
const SnapSet *snapset; //旧的SnapSet,也就是OSD服务端保存的快照信息
SnapSet new_snapset; // 新的SnapSet,也就是写操作过后生成的结果
SnapContext snapc; //写操作带的客户端的SnapContext信息
// ...
}
// ...
};
// 代码路径:src/osd/osd_types.h
// SnapSet 是在ceph的服务端(也就是osd端)保存快照集合的对象
struct SnapSet {
snapid_t seq; //最新的快照序列号
vector<snapid_t> snaps; // 所有快照序号的降序列表
vector<snapid_t> clones; // 所有clone对象的序号升序列表。保存在做完快照后,对原对象进行写入时触发cow进行clone的快照序号,注意并不是每个快照都需要clone对象,只有做完快照后,对相应的对象进行写入操作时才会clone去拷贝数据;
map<snapid_t, interval_set<uint64_t> > clone_overlap; // 与上次clone对象的overlap的部分,记录在其clone数据对象后,也就是原数据对象上未写过的数据部分,是采用offset~len的方式进行记录的,比如{2=[0~1646592,1650688~12288,1667072~577536]};
map<snapid_t, uint64_t> clone_size; //clone对象的size(有的对象一开始并不是默认的对象大小
SnapSet() : seq(0) {}
explicit SnapSet(ceph::buffer::list& bl) {
auto p = std::cbegin(bl);
decode(p);
}
/// librados::snap_set_t 发布快照
void from_snap_set(const librados::snap_set_t& ss, bool legacy);
// 数据处理
uint64_t get_clone_bytes(snapid_t clone) const;
void encode(ceph::buffer::list& bl) const;
void decode(ceph::buffer::list::const_iterator& bl);
void dump(ceph::Formatter *f) const;
static void generate_test_instances(std::list<SnapSet*>& o);
SnapContext get_ssc_as_of(snapid_t as_of) const {
SnapContext out;
out.seq = as_of;
for (auto p = clone_snaps.rbegin();
p != clone_snaps.rend();
++p) {
for (auto snap : p->second) {
if (snap <= as_of) {
out.snaps.push_back(snap);
}
}
}
return out;
}
SnapSet get_filtered(const pg_pool_t &pinfo) const;
void filter(const pg_pool_t &pinfo);
};
SnapContext 在客户端中保存 snap 相关的信息,是当前为对象定义的快照合集。 PrimaryLogPG 透过 SnapContext 跟踪对象的全部的快照集合,当前存在的全部克隆,克隆的大小。 PrimaryLogPG 通过 new_snap 和 snapc 的比较感知到快照已经过期;另外 SnapContext 的 clone_overlap 保存本次 clone 对象和上次 clone 对象的重叠(overlap)部分,clone 操作之后,每次的写操作都要维护这个信息。这个信息用于在数据恢复阶段对象恢复的优化。
make_writeable 中封装了一部分逻辑处理的功能,更详细的功能感兴趣的同学可以自己的看一下把整个流程梳理出来,篇幅有限这里就不再展开更多的源码内容。
void PrimaryLogPG::make_writeable(OpContext *ctx)
{
// ...
// 存在快照并且快照已经不是最新的
if ((ctx->obs->exists && !ctx->obs->oi.is_whiteout()) &&
snapc.snaps.size() &&
!ctx->cache_operation &&
snapc.snaps[0] > ctx->new_snapset.seq) {
hobject_t coid = soid;
coid.snap = snapc.seq;
const auto snaps = [&] {
auto last = find_if_not(
begin(snapc.snaps), end(snapc.snaps),
[&](snapid_t snap_id) { return snap_id > ctx->new_snapset.seq; });
return vector<snapid_t>{begin(snapc.snaps), last};
}();
// 准备 clone
object_info_t static_snap_oi(coid);
object_info_t *snap_oi;
if (is_primary()) {
ctx->clone_obc = object_contexts.lookup_or_create(static_snap_oi.soid);
ctx->clone_obc->destructor_callback =
new C_PG_ObjectContext(this, ctx->clone_obc.get());
ctx->clone_obc->obs.oi = static_snap_oi;
ctx->clone_obc->obs.exists = true;
ctx->clone_obc->ssc = ctx->obc->ssc;
ctx->clone_obc->ssc->ref++;
if (pool.info.is_erasure())
ctx->clone_obc->attr_cache = ctx->obc->attr_cache;
snap_oi = &ctx->clone_obc->obs.oi;
if (ctx->obc->obs.oi.has_manifest()) {
if ((ctx->obc->obs.oi.flags & object_info_t::FLAG_REDIRECT_HAS_REFERENCE) &&
ctx->obc->obs.oi.manifest.is_redirect()) {
snap_oi->set_flag(object_info_t::FLAG_MANIFEST);
snap_oi->manifest.type = object_manifest_t::TYPE_REDIRECT;
snap_oi->manifest.redirect_target = ctx->obc->obs.oi.manifest.redirect_target;
} else if (ctx->obc->obs.oi.manifest.is_chunked()) {
snap_oi->set_flag(object_info_t::FLAG_MANIFEST);
snap_oi->manifest.type = object_manifest_t::TYPE_CHUNKED;
snap_oi->manifest.chunk_map = ctx->obc->obs.oi.manifest.chunk_map;
} else {
ceph_abort_msg("unrecognized manifest type");
}
}
bool got = ctx->lock_manager.get_write_greedy(
coid,
ctx->clone_obc,
ctx->op);
ceph_assert(got);
dout(20) << " got greedy write on clone_obc " << *ctx->clone_obc << dendl;
} else {
snap_oi = &static_snap_oi;
}
snap_oi->version = ctx->at_version;
snap_oi->prior_version = ctx->obs->oi.version;
snap_oi->copy_user_bits(ctx->obs->oi);
_make_clone(ctx, ctx->op_t.get(), ctx->clone_obc, soid, coid, snap_oi);
ctx->delta_stats.num_objects++;
if (snap_oi->is_dirty()) {
ctx->delta_stats.num_objects_dirty++;
osd->logger->inc(l_osd_tier_dirty);
}
if (snap_oi->is_omap())
ctx->delta_stats.num_objects_omap++;
if (snap_oi->is_cache_pinned())
ctx->delta_stats.num_objects_pinned++;
if (snap_oi->has_manifest())
ctx->delta_stats.num_objects_manifest++;
ctx->delta_stats.num_object_clones++;
ctx->new_snapset.clones.push_back(coid.snap);
ctx->new_snapset.clone_size[coid.snap] = ctx->obs->oi.size;
ctx->new_snapset.clone_snaps[coid.snap] = snaps;
// 将快照重叠部分保存到 clone_overlap 中
ctx->new_snapset.clone_overlap[coid.snap];
if (ctx->obs->oi.size) {
ctx->new_snapset.clone_overlap[coid.snap].insert(0, ctx->obs->oi.size);
}
// log clone
dout(10) << " cloning v " << ctx->obs->oi.version
<< " to " << coid << " v " << ctx->at_version
<< " snaps=" << snaps
<< " snapset=" << ctx->new_snapset << dendl;
ctx->log.push_back(pg_log_entry_t(
pg_log_entry_t::CLONE, coid, ctx->at_version,
ctx->obs->oi.version,
ctx->obs->oi.user_version,
osd_reqid_t(), ctx->new_obs.oi.mtime, 0));
encode(snaps, ctx->log.back().snaps);
ctx->at_version.version++;
}
// 更新 clone_overlap 的数据和状态。
if (ctx->new_snapset.clones.size() > 0) {
hobject_t last_clone_oid = soid;
last_clone_oid.snap = ctx->new_snapset.clone_overlap.rbegin()->first;
interval_set<uint64_t> &newest_overlap =
ctx->new_snapset.clone_overlap.rbegin()->second;
ctx->modified_ranges.intersection_of(newest_overlap);
if (is_present_clone(last_clone_oid)) {
// modified_ranges is still in use by the clone
ctx->delta_stats.num_bytes += ctx->modified_ranges.size();
}
newest_overlap.subtract(ctx->modified_ranges);
}
// 更新快照信息
if (snapc.seq > ctx->new_snapset.seq) {
ctx->new_snapset.seq = snapc.seq;
if (get_osdmap()->require_osd_release < ceph_release_t::octopus) {
ctx->new_snapset.snaps = snapc.snaps;
} else {
ctx->new_snapset.snaps.clear();
}
}
dout(20) << "make_writeable " << soid
<< " done, snapset=" << ctx->new_snapset << dendl;
}
快照的回滚
快照的回滚,就是把当前的head对象,回滚到某个快照对象。 具体操作如下:
- 删除当前 head 对象的数据
- 拷贝相应的 snap 对象到 head 对象
假如有 foo 对象的快照结构如下所示,它想要回退到 snap[1] 的版本。
回滚前:
foo snap[1]: [chunk4] [chunk5]
foo snap[0]: [ chunk2 ]
foo head : [chunk1] [chunk3]
回滚后:
foo snap[1]: [chunk4] [chunk5]
foo snap[0]: [ chunk2 ]
foo head : [chunk4] [chunk5]
// 源码实现:src/osd/PrimaryLogPG.cc
int PrimaryLogPG::_rollback_to(OpContext *ctx, OSDOp& op)
{
ObjectState& obs = ctx->new_obs;
object_info_t& oi = obs.oi;
const hobject_t& soid = oi.soid;
snapid_t snapid = (uint64_t)op.op.snap.snapid;
hobject_t missing_oid;
dout(10) << "_rollback_to " << soid << " snapid " << snapid << dendl;
ObjectContextRef rollback_to;
int ret = find_object_context(
hobject_t(soid.oid, soid.get_key(), snapid, soid.get_hash(), info.pgid.pool(),
soid.get_namespace()),
&rollback_to, false, false, &missing_oid);
if (ret == -EAGAIN) {
/* clone must be missing */
ceph_assert(is_degraded_or_backfilling_object(missing_oid) || is_degraded_on_async_recovery_target(missing_oid));
dout(20) << "_rollback_to attempted to roll back to a missing or backfilling clone "
<< missing_oid << " (requested snapid: ) " << snapid << dendl;
block_write_on_degraded_snap(missing_oid, ctx->op);
return ret;
}
{
ObjectContextRef promote_obc;
cache_result_t tier_mode_result;
if (obs.exists && obs.oi.has_manifest()) {
/*
* In the case of manifest object, the object_info exists on the base tier at all time,
* so promote_obc should be equal to rollback_to
* */
promote_obc = rollback_to;
tier_mode_result =
maybe_handle_manifest_detail(
ctx->op,
true,
rollback_to);
} else {
tier_mode_result =
maybe_handle_cache_detail(
ctx->op,
true,
rollback_to,
ret,
missing_oid,
true,
false,
&promote_obc);
}
switch (tier_mode_result) {
case cache_result_t::NOOP:
break;
case cache_result_t::BLOCKED_PROMOTE:
ceph_assert(promote_obc);
block_write_on_snap_rollback(soid, promote_obc, ctx->op);
return -EAGAIN;
case cache_result_t::BLOCKED_FULL:
block_write_on_full_cache(soid, ctx->op);
return -EAGAIN;
case cache_result_t::REPLIED_WITH_EAGAIN:
ceph_abort_msg("this can't happen, no rollback on replica");
default:
ceph_abort_msg("must promote was set, other values are not valid");
return -EAGAIN;
}
}
if (ret == -ENOENT || (rollback_to && rollback_to->obs.oi.is_whiteout())) {
// there's no snapshot here, or there's no object.
// if there's no snapshot, we delete the object; otherwise, do nothing.
dout(20) << "_rollback_to deleting head on " << soid.oid
<< " because got ENOENT|whiteout on find_object_context" << dendl;
if (ctx->obc->obs.oi.watchers.size()) {
// Cannot delete an object with watchers
ret = -EBUSY;
} else {
_delete_oid(ctx, false, false);
ret = 0;
}
} else if (ret) {
// ummm....huh? It *can't* return anything else at time of writing.
ceph_abort_msg("unexpected error code in _rollback_to");
} else { //we got our context, let's use it to do the rollback!
hobject_t& rollback_to_sobject = rollback_to->obs.oi.soid;
if (is_degraded_or_backfilling_object(rollback_to_sobject) ||
is_degraded_on_async_recovery_target(rollback_to_sobject)) {
dout(20) << "_rollback_to attempted to roll back to a degraded object "
<< rollback_to_sobject << " (requested snapid: ) " << snapid << dendl;
block_write_on_degraded_snap(rollback_to_sobject, ctx->op);
ret = -EAGAIN;
} else if (rollback_to->obs.oi.soid.snap == CEPH_NOSNAP) {
// rolling back to the head; we just need to clone it.
ctx->modify = true;
} else {
if (rollback_to->obs.oi.has_manifest() && rollback_to->obs.oi.manifest.is_chunked()) {
OpFinisher* op_finisher = nullptr;
auto op_finisher_it = ctx->op_finishers.find(ctx->current_osd_subop_num);
if (op_finisher_it != ctx->op_finishers.end()) {
op_finisher = op_finisher_it->second.get();
}
if (!op_finisher) {
bool need_inc_ref = inc_refcount_by_set(ctx, rollback_to->obs.oi.manifest, op);
if (need_inc_ref) {
ceph_assert(op_finisher_it == ctx->op_finishers.end());
ctx->op_finishers[ctx->current_osd_subop_num].reset(
new SetManifestFinisher(op));
return -EINPROGRESS;
}
} else {
op_finisher->execute();
ctx->op_finishers.erase(ctx->current_osd_subop_num);
}
}
_do_rollback_to(ctx, rollback_to, op);
}
}
return ret;
}
快照的删除
向 monitor 集群发出请求,将快照的 id 添加到已清除的快照的列表中。删除快照时,直接删除SnapSet相关的信息,并删除相应的快照对象。其调用流程可参看快照的创建流程。
ceph的删除是延迟删除,并不直接删除。当 pg 是 clean 状态并且没进行 scrubbing 时由由 snap_trimq 异步执行。
// 相关源码:src/osd/PrimaryLogPG.h
class PrimaryLogPG : public PG, public PGBackend::Listener {
friend class OSD;
friend class Watch;
friend class PrimaryLogScrub;
// ...
struct SnapTrimmer : public boost::statechart::state_machine< SnapTrimmer, NotTrimming > {
PrimaryLogPG *pg;
explicit SnapTrimmer(PrimaryLogPG *pg) : pg(pg) {}
void log_enter(const char *state_name);
void log_exit(const char *state_name, utime_t duration);
bool permit_trim();
bool can_trim() {
return
permit_trim() &&
!pg->get_osdmap()->test_flag(CEPH_OSDMAP_NOSNAPTRIM);
}
} snap_trimmer_machine;
};
CephFS快照
CephFS 通过在希望快照的目录下执行 mkdir 创建 .snap 目录来创建快照。这时 fs 客户端会生成一个 SnapRealm,它保留较少的数据,用于将 SnapContex 与每个打开的文件关联以进行写入。 SnapRealm 中包含 srnode(磁盘上的元数据,包含序列计数器,时间戳,相关的快照 id 列表和 past_parents) , past_parents , past_children , inodes_with_caps 等属于快照的一部分的信息。
// 代码路径: https://github.com/ceph/ceph-client/fs/ceph/dir.c
static int ceph_mkdir(struct user_namespace *mnt_userns, struct inode *dir,
struct dentry *dentry, umode_t mode)
{
struct ceph_mds_client *mdsc = ceph_sb_to_mdsc(dir->i_sb);
struct ceph_mds_request *req;
struct ceph_acl_sec_ctx as_ctx = {};
int err;
int op;
err = ceph_wait_on_conflict_unlink(dentry);
if (err)
return err;
// 目录格式为 .snap/foo 则进入快照处理逻辑
if (ceph_snap(dir) == CEPH_SNAPDIR) {
/* mkdir .snap/foo is a MKSNAP */
op = CEPH_MDS_OP_MKSNAP;
dout("mksnap dir %p snap '%pd' dn %p\n", dir,
dentry, dentry);
} else if (ceph_snap(dir) == CEPH_NOSNAP) {
dout("mkdir dir %p dn %p mode 0%ho\n", dir, dentry, mode);
op = CEPH_MDS_OP_MKDIR;
} else {
err = -EROFS;
goto out;
}
if (op == CEPH_MDS_OP_MKDIR &&
ceph_quota_is_max_files_exceeded(dir)) {
err = -EDQUOT;
goto out;
}
mode |= S_IFDIR;
err = ceph_pre_init_acls(dir, &mode, &as_ctx);
if (err < 0)
goto out;
err = ceph_security_init_secctx(dentry, mode, &as_ctx);
if (err < 0)
goto out;
req = ceph_mdsc_create_request(mdsc, op, USE_AUTH_MDS);
if (IS_ERR(req)) {
err = PTR_ERR(req);
goto out;
}
req->r_dentry = dget(dentry);
req->r_num_caps = 2;
req->r_parent = dir;
ihold(dir);
set_bit(CEPH_MDS_R_PARENT_LOCKED, &req->r_req_flags);
req->r_args.mkdir.mode = cpu_to_le32(mode);
req->r_dentry_drop = CEPH_CAP_FILE_SHARED | CEPH_CAP_AUTH_EXCL;
req->r_dentry_unless = CEPH_CAP_FILE_EXCL;
if (as_ctx.pagelist) {
req->r_pagelist = as_ctx.pagelist;
as_ctx.pagelist = NULL;
}
err = ceph_mdsc_do_request(mdsc, dir, req);
if (!err &&
!req->r_reply_info.head->is_target &&
!req->r_reply_info.head->is_dentry)
err = ceph_handle_notrace_create(dir, dentry);
ceph_mdsc_put_request(req);
out:
if (!err)
ceph_init_inode_acls(d_inode(dentry), &as_ctx);
else
d_drop(dentry);
ceph_release_acl_sec_ctx(&as_ctx);
return err;
}
当执行快照操作的时候,客户端会将请求发送到 MDS 服务器,然后在服务器的 Server::handle_client_mksnap() 中处理,它会从 SnapServer 中非配一个 snapid ,同时利用新的 SnapRealm 创建一个新的 inode ,然后将其提交到 MDlog ,提交后会触发 MDCache::do_realm_invalidate_and_update_notify() ,快照的大部分工作由这部分完成。快照的元数据会作为目录信息的一部分被存储在 OSD 端。
代码路径:https://github.com/ceph/ceph
void Server::handle_client_mksnap(MDRequestRef& mdr)
{
// ...
// 服务端会通过 snapclient 与 snapserver 进行通信
// 创建 snapid
if (!mdr->more()->stid) {
mds->snapclient->prepare_create(diri->ino(), snapname,
mdr->get_mds_stamp(),
&mdr->more()->stid, &mdr->more()->snapidbl,
new C_MDS_RetryRequest(mdcache, mdr));
return;
}
version_t stid = mdr->more()->stid;
snapid_t snapid;
auto p = mdr->more()->snapidbl.cbegin();
decode(snapid, p);
dout(10) << " stid " << stid << " snapid " << snapid << dendl;
ceph_assert(mds->snapclient->get_cached_version() >= stid);
SnapPayload payload;
if (req->get_data().length()) {
try {
auto iter = req->get_data().cbegin();
decode(payload, iter);
} catch (const ceph::buffer::error &e) {
// backward compat -- client sends xattr bufferlist. however,
// that is not used anywhere -- so (log and) ignore.
dout(20) << ": no metadata in payload (old client?)" << dendl;
}
}
// 日志
SnapInfo info;
info.ino = diri->ino();
info.snapid = snapid;
info.name = snapname;
info.stamp = mdr->get_op_stamp();
info.metadata = payload.metadata;
auto pi = diri->project_inode(mdr, false, true);
pi.inode->ctime = info.stamp;
if (info.stamp > pi.inode->rstat.rctime)
pi.inode->rstat.rctime = info.stamp;
pi.inode->rstat.rsnaps++;
pi.inode->version = diri->pre_dirty();
auto &newsnap = *pi.snapnode;
newsnap.created = snapid;
auto em = newsnap.snaps.emplace(std::piecewise_construct, std::forward_as_tuple(snapid), std::forward_as_tuple(info));
if (!em.second)
em.first->second = info;
newsnap.seq = snapid;
newsnap.last_created = snapid;
// 日志记录 inode 的变化
mdr->ls = mdlog->get_current_segment();
EUpdate *le = new EUpdate(mdlog, "mksnap");
mdlog->start_entry(le);
le->metablob.add_client_req(req->get_reqid(), req->get_oldest_client_tid());
le->metablob.add_table_transaction(TABLE_SNAP, stid);
mdcache->predirty_journal_parents(mdr, &le->metablob, diri, 0, PREDIRTY_PRIMARY, false);
mdcache->journal_dirty_inode(mdr.get(), &le->metablob, diri);
// 日志记录 snaprealm 的变化
submit_mdlog_entry(le, new C_MDS_mksnap_finish(this, mdr, diri, info),
mdr, __func__);
mdlog->flush();
}
需要注意的是 CephFS 的快照和多个文件系统的交互是存在问题的——每个 MDS 集群独立分配 snappid,如果多个文件系统共享一个池,快照会冲突。如果此时有客户删除一个快照,将会导致其他人丢失数据,并且这种情况不会抛出异常,这也是 CephFS 的快照不推荐使用的原因。
克隆卷
克隆卷的操作必须要在快照被保护起来(无法删除)之后才能进行。在克隆卷生成之后,在 librbd 端开始读写时会先根据快照链构造出其父子关系,而在具体的 I/O 请求的时候这个父子关系会被用到。克隆出的卷在有新数据写入之前,读取数据的需求都是引用父卷和快照的数据。
对于克隆卷的读写会先去找这个卷的对象,如果未找到,就去寻找其 parent 对象,层层往上,直到找到位置。所以一旦快照链比较长就会导致效率较低,所以 Ceph 的克隆卷提供了 flatten 功能,这个功能会将所有的数据全部拷贝一份,然后生成一个新的卷。新生成的卷会完全独立存在,不再保持原有的父子关系。但是 flatten 本身是一个耗时比较大的操作。
更多技术分享浏览我的博客:
https://thierryzhou.github.io